이번 포스팅은 Glue Studio로 반정형 데이터에 대한 ETL 작업을 해 보겠습니다.
0. 개요
ETL작업은 필요한 데이터를 만들기 위해 원본 데이터를 사용자의 목적에 맞도록 가공하는 작업입니다. AWS Glue는 단지 ETL작업만 지원하기 때문에, 이 ETL작업을 통해 어떤 데이터로 가공할 것 인지에 대해 생각해야 합니다.
이러한 ETL작업에서 가장 중요한 관점은 “목적성” 입니다. 사용자는 AI모델을 만들거나, 로그 분석을 통해 장애를 파악하는 등의 데이터가 필요한 “목적”이 있습니다. 이를 위해 ETL작업은 “목적성”이 있어야 원하는 데이터로 가공을 할 수 있습니다.
이번 포스팅에서의 Hands On으로 AWS에서 Webina로 진행한 Glue – Sagemaker의 예를 Glue Studio로 수행하겠습니다.
우리에게는 예시 데이터로 아마존 쇼핑몰의 리뷰 데이터가 있다고 가정합시다. 이 데이터를 가지고만 있으면 아무것도 아닌, 단순한 리뷰 데이터입니다.
만약 우리에게 아래와 같은 과제가 주어졌다고 합시다.
<온라인 쇼핑몰의 리뷰 내용으로 카테고리를 유추할 수 있는 머신러닝 모델>

우리에게는 머신러닝 모델을 만들 수 있는, 즉 “목적”을 달성할 수 있는 데이터가 필요합니다. 다시말하면, 우리가 가지고 있는 아마존 쇼핑몰의 리뷰 데이터를 가지고 머신러닝 모델을 만들 “목적성”을 가질 수 있게 됩니다.
이번 포스팅에서 “목적성”을 달성하기 위해 우리는 가지고 있는 아마존 쇼핑몰 리뷰 데이터를 가지고 머신러닝을 수행할 수 있는 데이터로 ETL작업을 Hands On을 통해 진행하겠습니다.
Hands On을 진행하기 위해서는 쇼핑몰의 리뷰에 해당하는 데이터가 필요합니다. Amazon에서는 이러한 모델을 만드는 것을 지원하기 위해 Amazon 쇼핑몰의 review데이터를 제공합니다.
링크 : https://s3.amazonaws.com/amazon-reviews-pds/readme.html
Hands On의 ETL 작업은 다음과 같은 순서로 이루어 집니다.
- Data Crawling
- Data Analyzing
- Data Partitioning
- Data Balancing
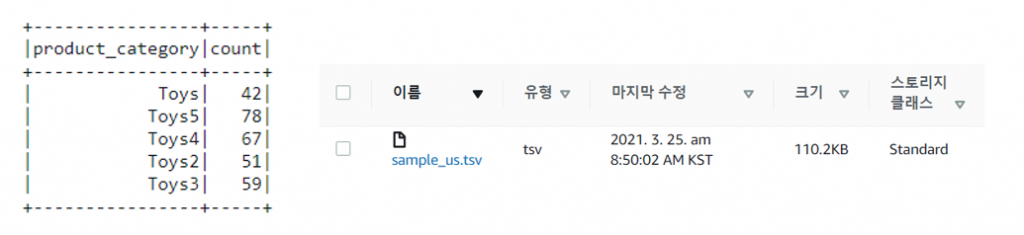
Hands On에서는 원활한 테스트를 위해 Amazon Review 데이터의 sample_us.tsv 파일을 이용합니다.
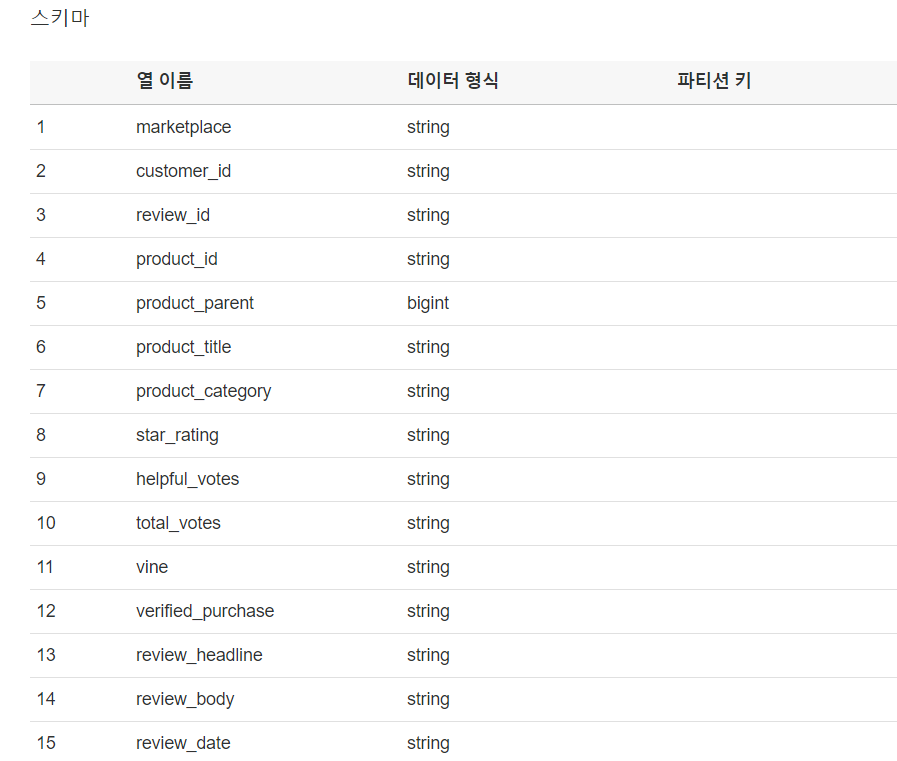
또한 여러 카테고리에 대한 Partitioning을 테스트하기 위해 sample_us.tsv파일을 임의 복제 하였습니다. 다음의 사진은 임의 복제한 파일의 데이터 수 및 schema 입니다.
1. Data Crawling
Glue에서는 Data를 직접 가져오는 것이 아닌, Data의 메타데이터만을 가져와서 데이터 카탈로그에 저장합니다.
<메타데이터와 데이터 카탈로그는 무엇일까요?>
메타데이터란, 데이터의 특성을 나타낸 것으로 크롤링된 데이터의 크기, 데이터의 형식, 스키마 등등으로 원본 데이터를 표현한 데이터입니다.
데이터 카탈로그는 이러한 메타데이터 들을 모아 한눈에 여러 데이터들을 확인할 수 있도록 해주는 기능입니다. Glue 에서는 “테이블”이라는 이름으로 데이터 카탈로그가 존재하며, 저장된 모든 메타데이터 들을 확인할 수 있으며 스키마 수정 등 간단한 메타데이터에 대한 작업을 할 수 있습니다.
작업을 할 때마다 모든 데이터를 가져오게 된다면 어떻게 될까요? 데이터의 양이 MB수준이면 가능하겠지만, GB, TB수준까지만 올라도 매우 큰 네트워크 트래픽이 발생할 것 입니다. 이를 방지하기 위해, 최후의 데이터 가공까지 원본 데이터를 옮기지 않습니다.(DB의 Lazy Evaluation과 비슷한 맥락입니다.)
Data의 메타데이터를 가져오는 작업은 Glue Crawler를 통해 할 수 있습니다.
[AWS Glue] -> [크롤러] -> [크롤러 추가]
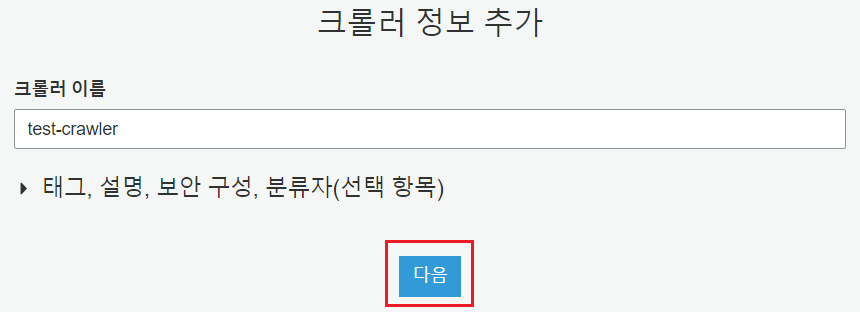
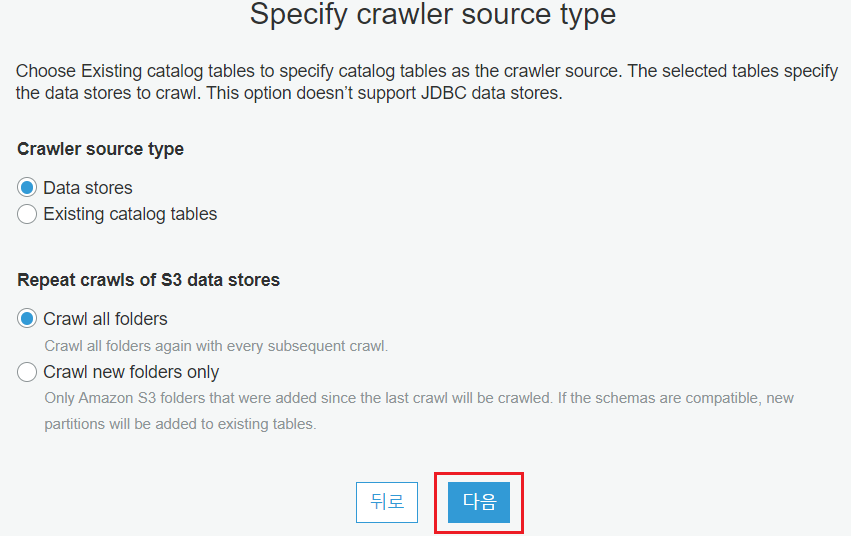
Crawler가 크롤링할 데이터 스토리지의 타입을 선택합니다. Data Stores는 AWS의 데이터 스토리지 서비스들(e.g. S3, RDS, Redshift, etc)을 의미합니다.
Existing catalog tables는 기존 Crawler가 생성한 카탈로그에 대해 크롤링을 할 수 있습니다. 이를 통해 Glue는 원본 데이터의 변경 없이 데이터를 정제하고, 정제된 데이터에 해당하는 메타데이터를 가지고 있을 수 있습니다.
Crawler는 한번의 크롤링만 하는 것이 아니라 주기적으로 실행할 필요가 있습니다. 그래서 Crawler가 실행될 때 모든 폴더를 크롤링 할지, 이미 크롤링된 데이터는 제외하고 새로운 폴더들에 대해서만 크롤링 할지 정할 수 있습니다.
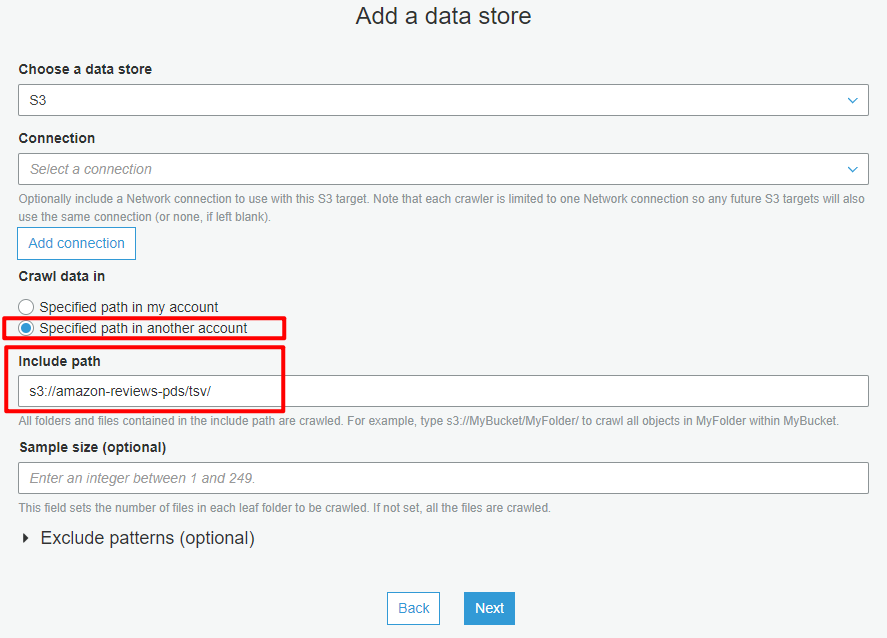
크롤링 할 데이터가 있는 데이터 스토어의 종류를 선택합니다.
연결(Connections)은 데이터 스토어가 사용자의 VPC안에 있을 때 연결하기 위한 End point와 같은 개념입니다. 이를 통해 네트워크에 공개되지 않은 사용자 환경의 데이터를 가져올 수 있습니다.
크롤링할 데이터의 위치가 내 계정 내부인지, 외부인지 설정해야 합니다. 다른 계정 소유의 버킷에 접근하려면 내 계정에 대한 접근을 허용하거나, 버킷이 Public으로 접근 가능해야 합니다.
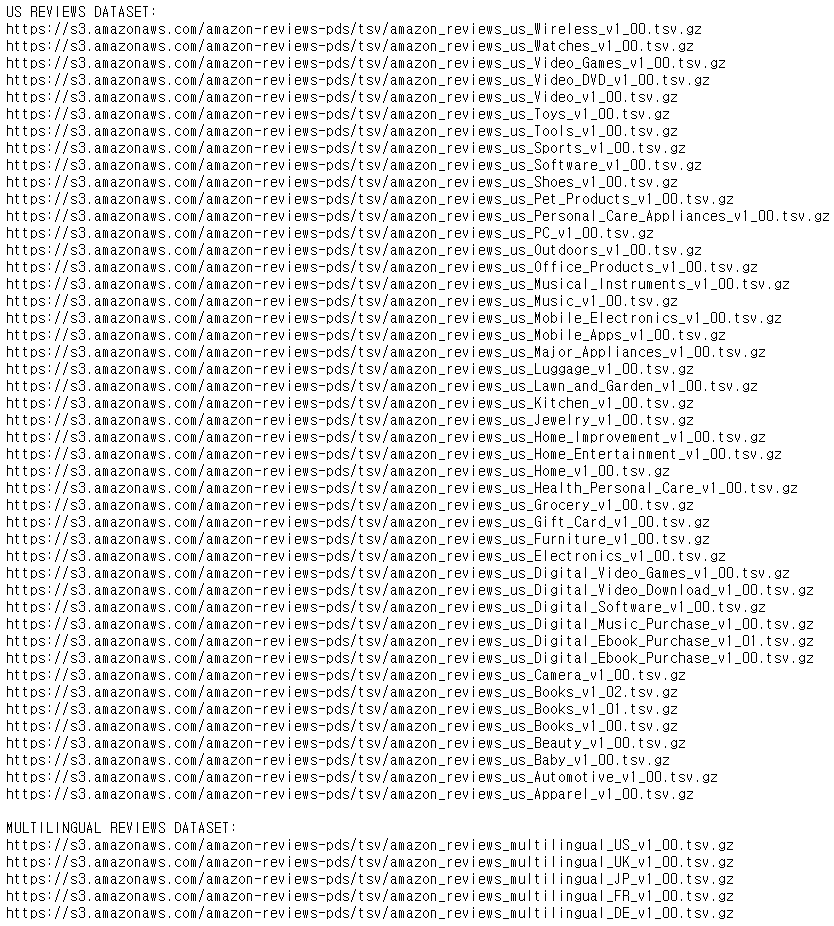
크롤링할 데이터를 가지고 있는 폴더의 index입니다. 명확한 데이터 활용을 위해 English와 None English로 나뉘어져 있습니다. 지금 필요한 데이터는 English만 저장된 데이터가 필요하기 때문에 예외처리를 해야 합니다.

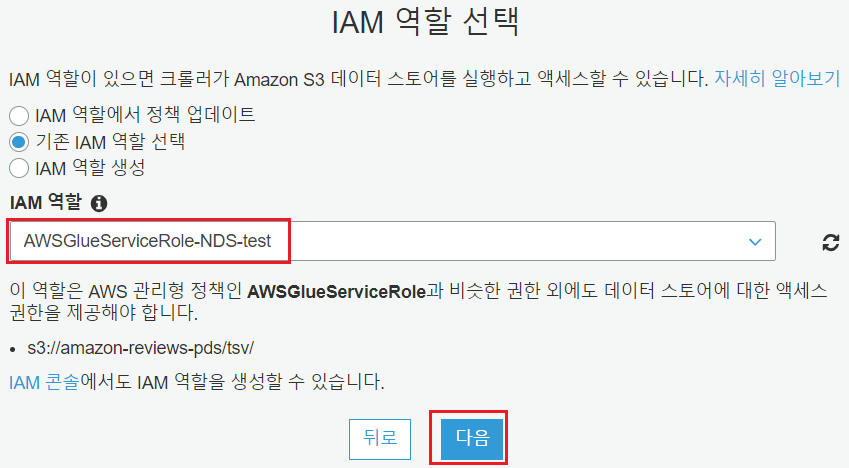
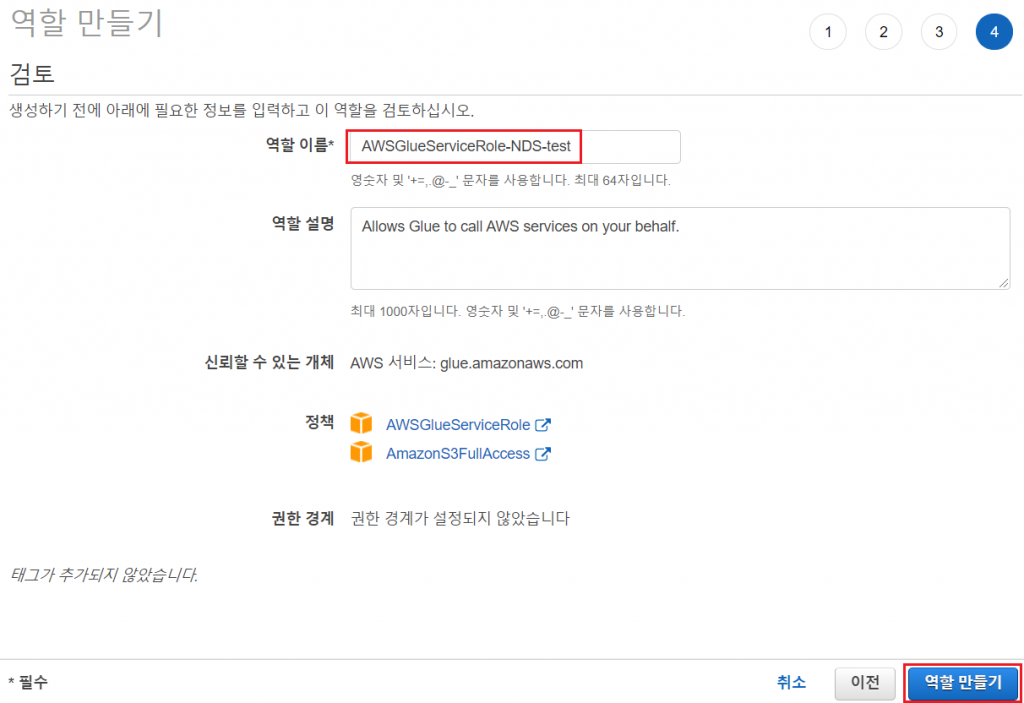
Glue에서 선택한 데이터 스토어에 접근할 수 있는 적절한 정책이 필요합니다. Hands On 에서는 S3 접근이 필요하기 때문에 S3접근을 허용한 역할을 만들어 사용했습니다.
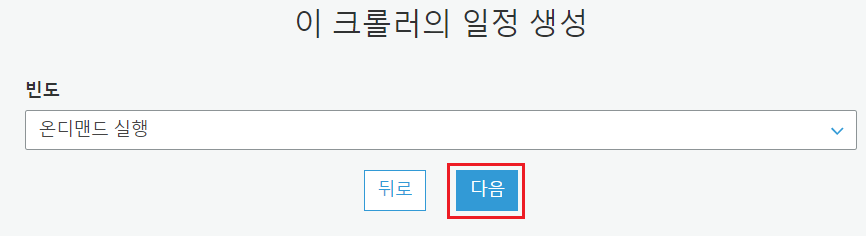
Crawler가 실행될 주기를 선택할 수 있습니다. 데이터가 가변하는 환경에서는 주기적으로 실행되야 하기 때문에 시간/일/주/월 별로 선택하거나, Cron 식을 통해 설정할 수 있습니다.
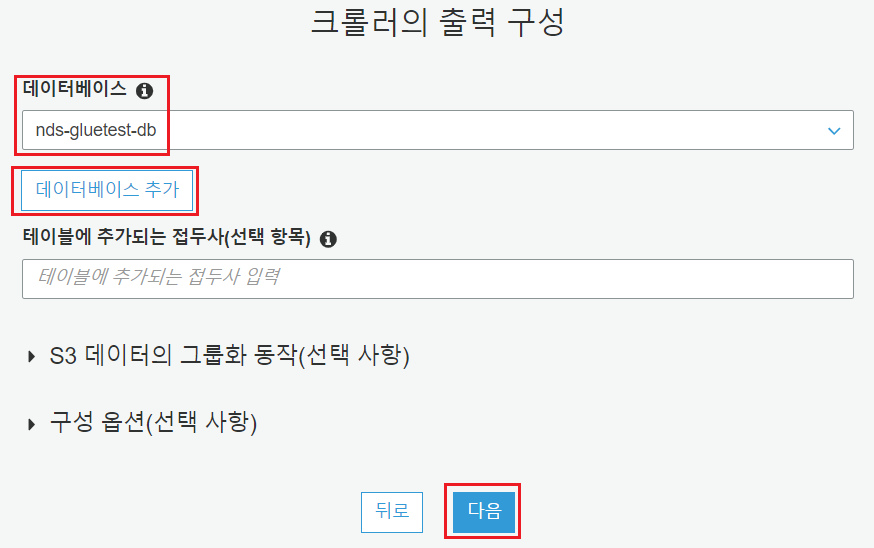
Crawler가 실행되고 난 후, 어느 데이터베이스에 카탈로그를 생성할 수 있는 옵션입니다. Glue에서 데이터베이스는 카탈로그의 논리적인 그룹이므로 엔진이나 사용자가 있는 것이 아닙니다.
Crawler가 생성되면 온디멘드 실행을 통해 크롤링을 시작할 수 있습니다.
2. Data Analyzing
Glue Crawler를 통해 원본 데이터에 대한 메타데이터를 얻었다면, 목적에 맞게 가공을 해야 합니다.
목적에 맞게 데이터를 가공하려면 어떻게 해야 할까요? 답은 먼저 데이터를 살펴봐야 합니다. 데이터 엔지니어의 관점으로 데이터의 특징을 파악하고, 데이터의가공 방향을 정해야 합니다.
잘못된 관점으로 데이터를 가공한다면, 가공된 데이터로 머신러닝 모델을 만들면 그 모델은 정확도가 낮은, 실패한 머신러닝 모델일 것 입니다.
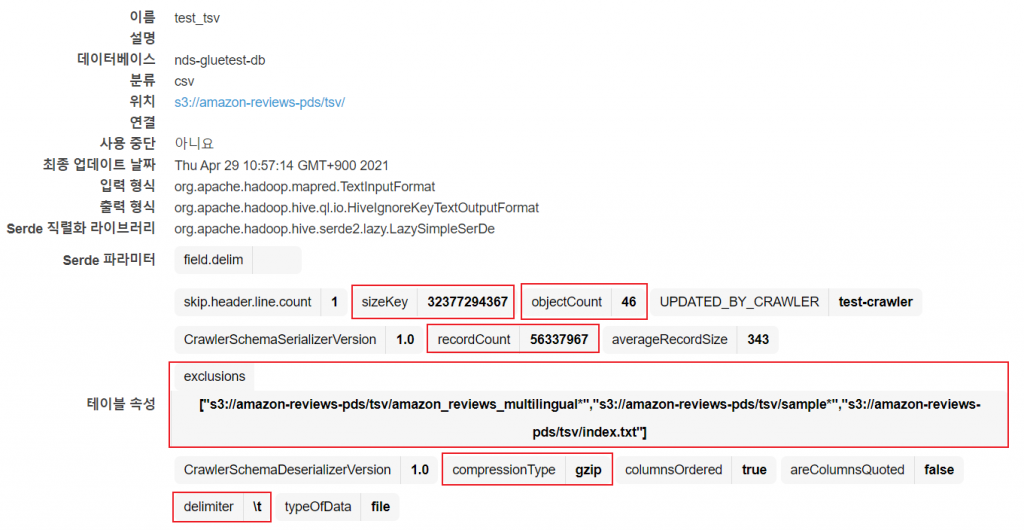
Crawler를 통해 생성된 테이블을 클릭하면 다음과 같이 크롤링된 데이터의 메타데이터를 얻을 수 있습니다.
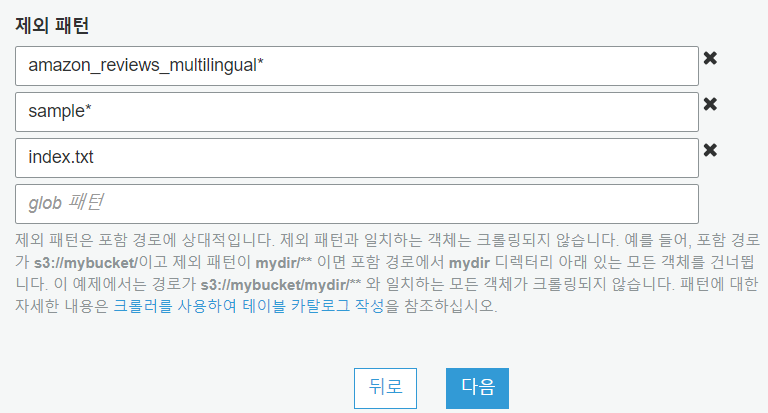
제외패턴을 통해 다중 언어 데이터가 제외되었으며, 압축은 gzip으로 되었고, 구분자는 탭(\t)으로 이루어진 데이터라는 정보를 얻을 수 있습니다.
데이터의 크기는 약 30GB이고, tsv파일 54개에서 english로만 이루어진 파일이 아닌 것을 제외한 46개 입니다.
이제 데이터를 Glue에서 사용할 준비가 되었으며, 데이터의 어떤 Column이 필요한 지, 어떤 Row가 필요한 지 생각할 필요가 있습니다.
1) review와 category를 제외한 column을 drop
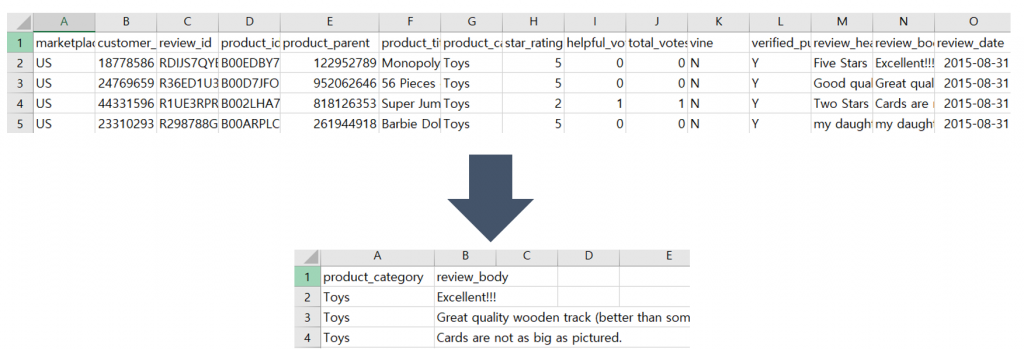
머신러닝 모델은 input으로 review 데이터만을 사용하여 category를 예측하는 모델입니다. 따라서 데이터의 review와 category를 제외한 다른 column들은 필요가 없습니다.
2) 너무 짧은 review 데이터 삭제

review의 길이가 너무 짧은 데이터로 모델을 training을 하게 된다면 모델의 정확도가 줄어들 수 있습니다. 따라서 기준을 정하고 기준보다 짧은 데이터를 삭제해야 합니다.
3) 각 데이터의 category 별로 균등한 데이터 셋
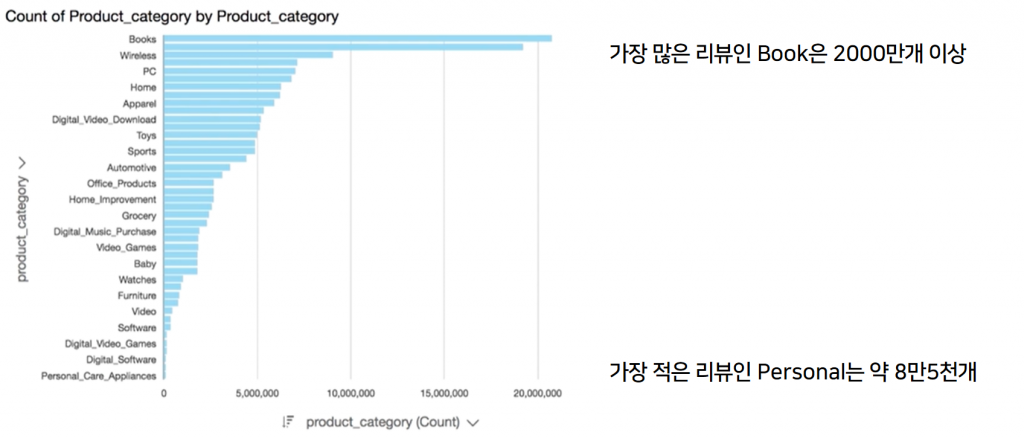
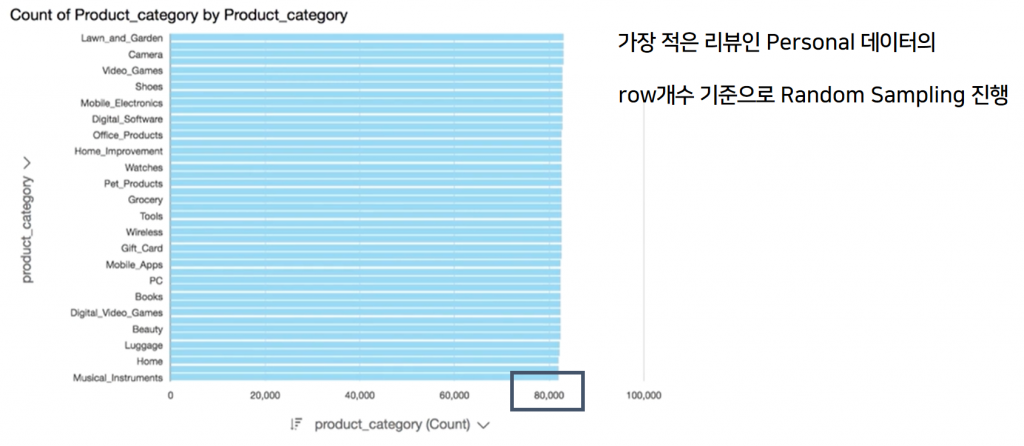
각 데이터의 category 별로 가진 데이터의 개수가 비슷해야 합니다. 한 category의 데이터가 많다면 훈련을 할 때 해당 category의 결과로 치우쳐 훈련되기 때문에 overfitting 문제가 발생하게 됩니다.
3. Data Partitioning
본 포스팅에서는 원활한 Hands On 진행을 위해 소량의 데이터셋을 가지고 진행합니다. 30GB가 넘는 데이터를 이용하여 Glue 작업 시 비용문제가 발생할 수 있기 때문입니다.
이제 우리가 필요한 데이터를 가공하는 단계입니다. 데이터 가공작업과 동시에 파티셔닝을 진행합니다.
데이터 파티셔닝은 DB와 마찬가지로, 비슷한 데이터들을 한 곳에 모아 필요한 데이터를 가져올 때 효율적으로 가져올 수 있게 됩니다.
전체 데이터를 스캔하여, 필요한 데이터를 추출하는 방식보다, 필요한 데이터가 있는 위치만을 스캔하여 가져오는 것이 데이터 스캔에 드는 비용을 절감할 수 있기 때문입니다.
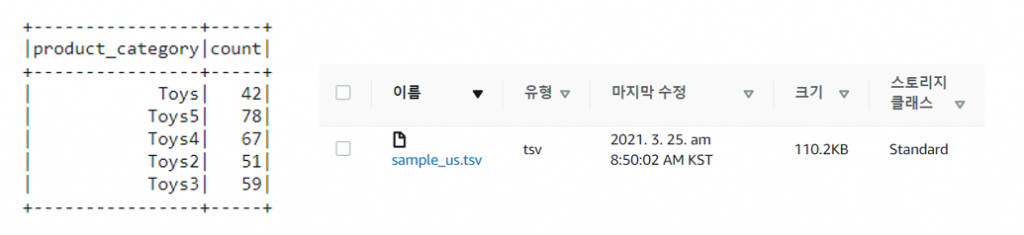
sample_us.tsv 파일은 제공된 리뷰 데이터의 샘플 파일로 category column이 toy인 파일입니다. 이 파일의 데이터를 중복 생성 하여서 위와 같은 스키마를 가지도록 변경했습니다.
Data Partitioning 단계에서는 그림과 같은 단계를 실행합니다.
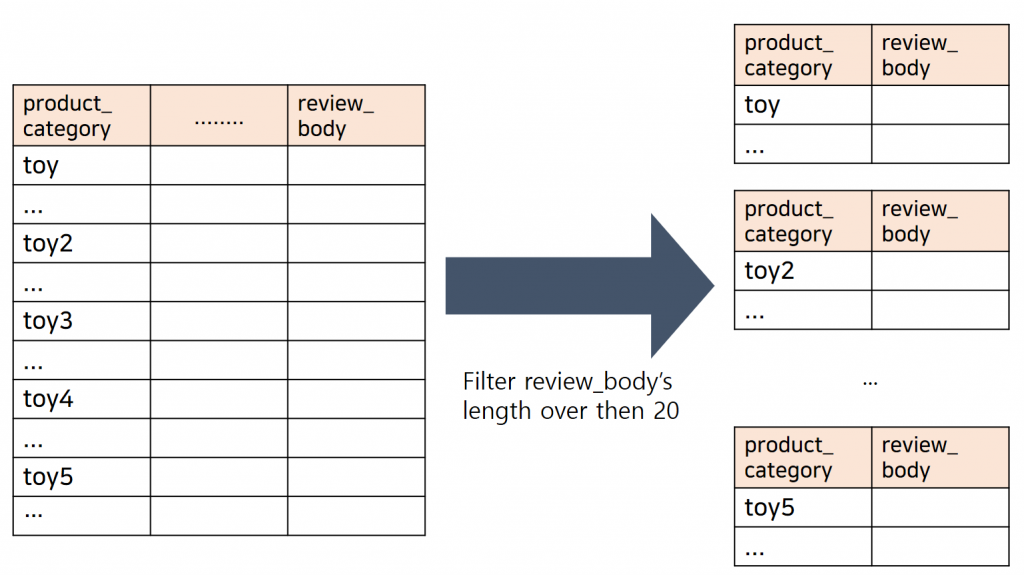
1) Source Node 생성
Source Node는 우리가 가지고 있는 데이터의 위치를 정할 수 있습니다.
데이터는 현재 S3에 보관되어 있습니다.
여기서, Glue Crawler를 이용하여 생성한 데이터 카탈로그를 사용할 수 있지만, Hands On에서는 원본데이터를 가지고 파티션을 생성하는 과정을 진행합니다.
2) Filter Node 생성
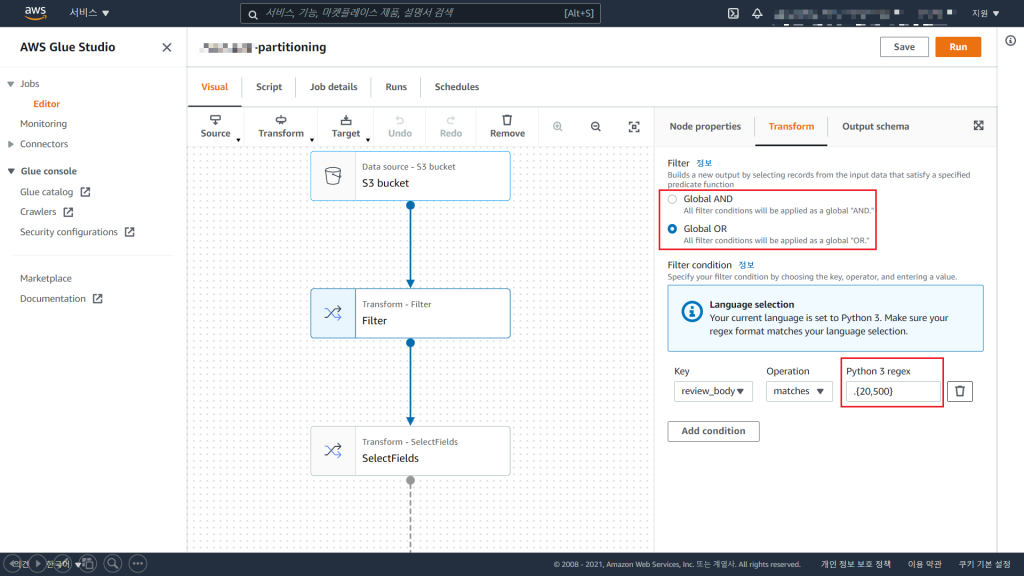
Filter Node를 통해 Data Analyzing 2)너무 짧은 review 데이터 삭제 를 합니다.
Python3의 정규식을 통해 20글자부터 500글자까지의 review 데이터만을 남기도록 합니다.
3) SelectFields Node 생성
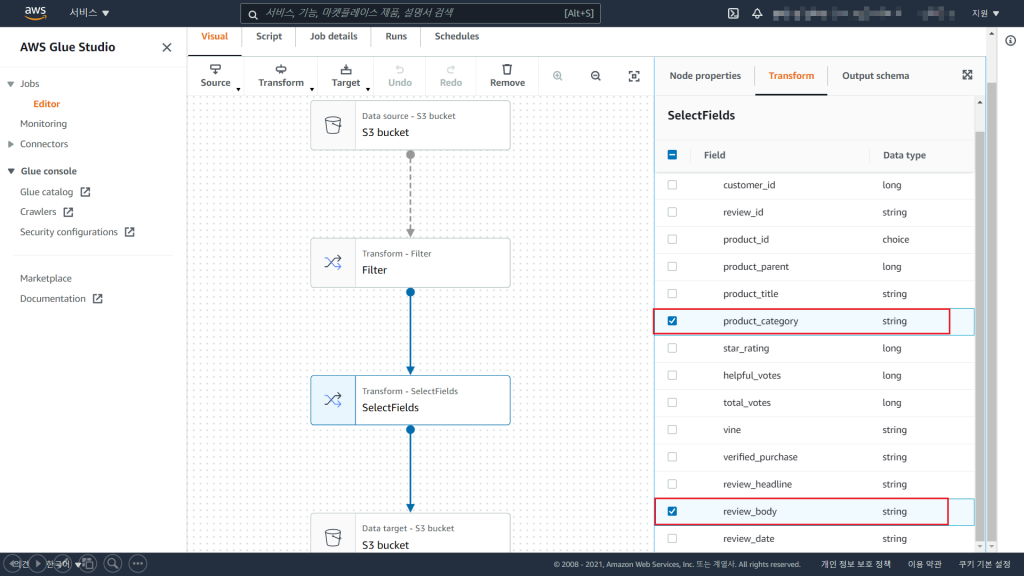
SelectField Node를 통해 Data Analyzing 1)의 review와 category를 제외한 column을 drop 을 합니다.
4) Target Node 생성
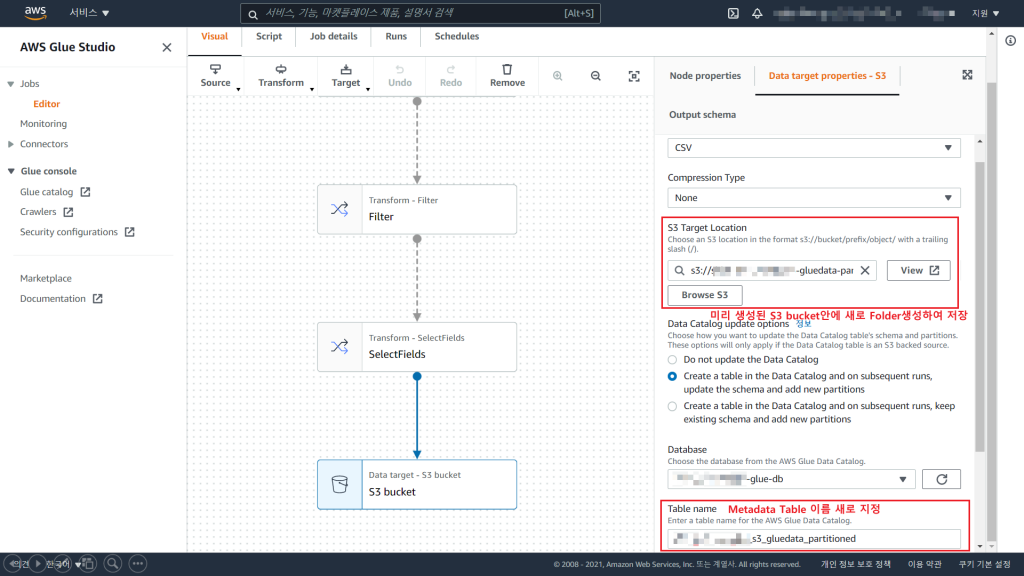
Target Node를 통해 데이터 가공 후 저장될 데이터 스토어 위치를 정할 수 있습니다.
Hands On에서는 S3로 이동하여, 파티셔닝이 어떤 과정을 통해 이루어지는지 확인하기 위해 S3을 Target으로 하였습니다. 데이터의 위치는 버킷만 존재한다면, 폴더를 자동으로 생성하게끔 위치를 설정할 수 있습니다.
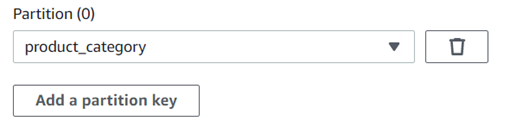
Target Node 설정 맨 아래에 Partition Key 추가를 통해 데이터 파티셔닝을 할 수 있습니다.
5) 결과 확인
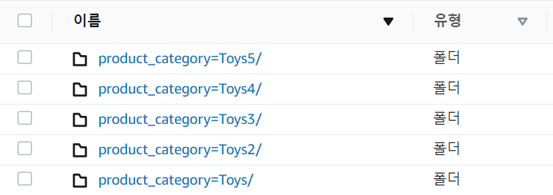
Glue Studio를 통해 데이터 가공, 파티셔닝을 하게 되면 다음과 같이 폴더가 생성되어, 각각 다른 경로에 데이터가 생성됩니다.
파일명을 이용하여 필요한 데이터만을 가져올 수 있게 되며, 원본 데이터를 가져올 때 비용이 절감되게 됩니다.
4. Data Balancing
이제 남은 과정은 Data Analyzing 3)각 데이터의 category 별로 균등한 데이터 셋 을 만드는 과정입니다.
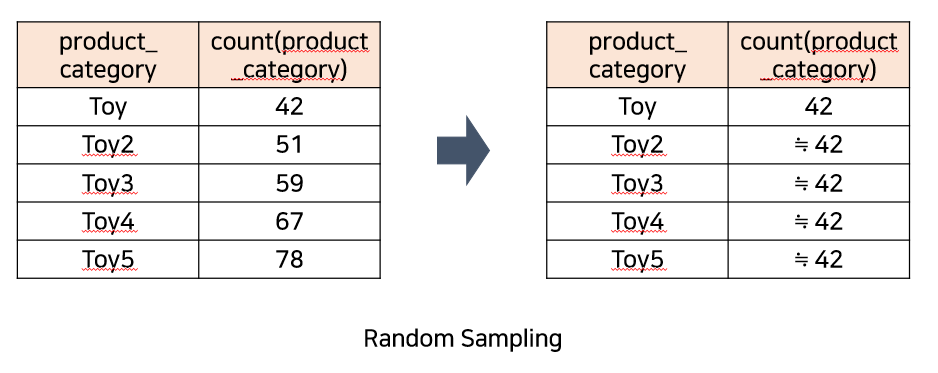
가장 적은 데이터를 가진 파티션의 데이터수와 같게끔 다른 파티션들을 샘플링하여 모든 파티션들이 같은 데이터 수를 가지도록 하는 것이 핵심입니다.
해당 과정은 어떻게 해야 할까요? 프로그래밍 적으로 접근한다면, 간단한 과정입니다. 전체 데이터들 중 가장 적은 데이터의 개수를 각각 파티션의 데이터 개수로 나눈다면, 각각의 파티션에서 필요한 데이터의 비율을 구할 수 있을 것 입니다.

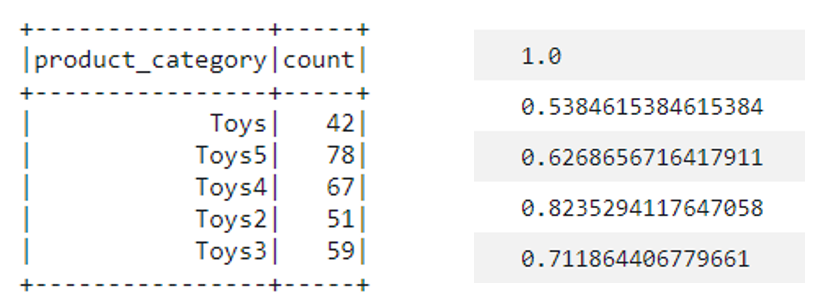
각각의 파티션이 가진 데이터 수와, 샘플링 해야하는 비율입니다.
해당 작업을 Glue Studio를 통해 진행해 보겠습니다.
1) Custom transform Node 생성
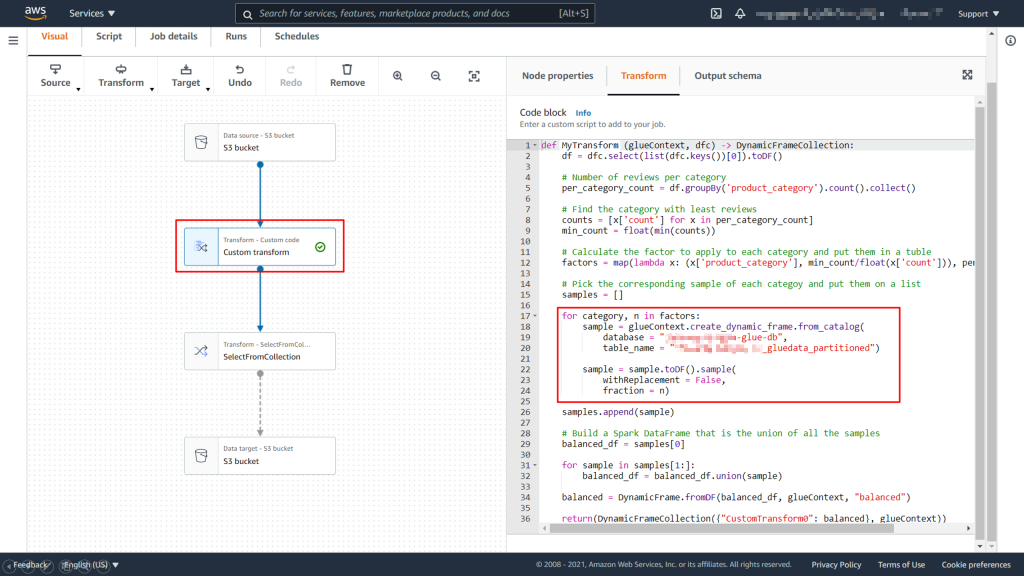
Balancing 작업은 Glue Studio를 통해 따로 지원되지 않기 때문에, PySpark 코드를 작성하여 진행합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
def MyTransform (glueContext, dfc) -> DynamicFrameCollection: df = dfc.select(list(dfc.keys())[0]).toDF() # Number of reviews per category per_category_count = df.groupBy('product_category').count().collect() # Find the category with least reviews counts = [x['count'] for x in per_category_count] min_count = float(min(counts)) # Calculate the factor to apply to each category and put them in a tuble factors = map(lambda x: (x['product_category'], min_count/float(x['count'])), per_category_count) # Pick the corresponding sample of each categoy and put them on a list samples = [] for category, n in factors: sample = glueContext.create_dynamic_frame.from_catalog( database = "<db 이름>", table_name = "<table 이름>") sample = sample.toDF().sample( withReplacement = False, fraction = n) samples.append(sample) # Build a Spark DataFrame that is the union of all the samples balanced_df = samples[0] for sample in samples[1:]: balanced_df = balanced_df.union(sample) balanced = DynamicFrame.fromDF(balanced_df, glueContext, "balanced") return(DynamicFrameCollection({"CustomTransform0": balanced}, glueContext)) |
원리는 각각 파티셔닝이 진행될 때 샘플링할 비율을 코드로 가져와 진행하는 것 입니다.
2) SelectFromCollection Node 생성
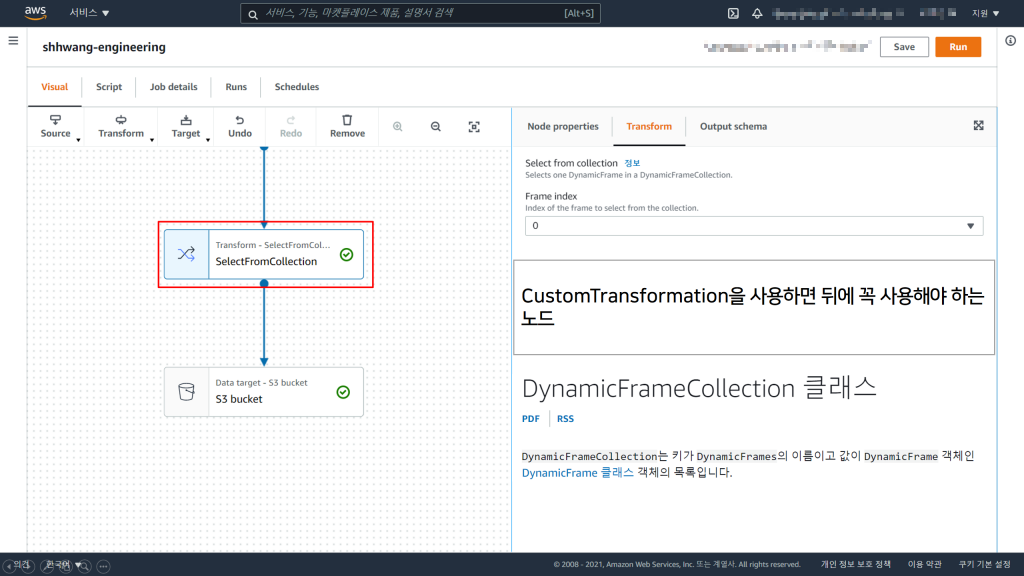
CustomTransformation을 한다면, 우리는 Spark에서 사용하는 DataFrame이 아닌, Glue에서 사용하는 DynamicFrame의 형태로 반환받게 됩니다. 이를 다시 DataFrame으로 변환시켜야, Glue가 Output으로 내보낼 수 있게 됩니다.
3) Target Node 생성
이로써, 우리가 원하는 데이터의 가공이 완료되었습니다. 생성된 Spark의 DataFrame을 원하는 위치, 파일 포맷, 압축 등의 옵션을 설정하여 내보낼 수 있게 됩니다.
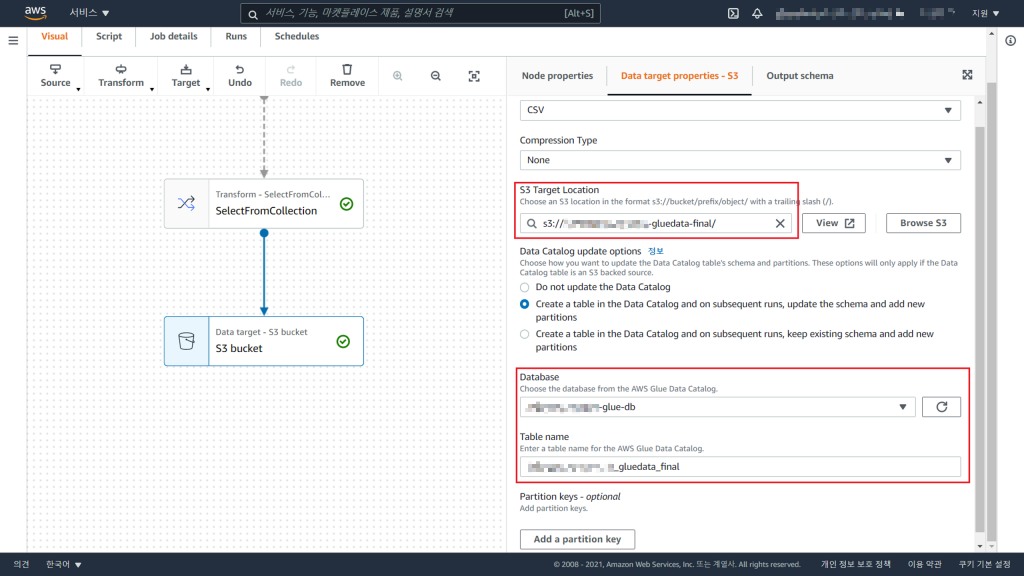
Hands On에서는 직접 다운받아 데이터를 확인하기 위해 S3로 csv파일로 내보냅니다.
5. Final Result
이제 우리는 우리에게 주어진 과제인 <온라인 쇼핑몰의 리뷰 내용으로 카테고리를 유추할 수 있는 머신러닝 모델>를 만들 수 있는 데이터 가공을 완료하였습니다. 데이터를 확인하면 다음과 같습니다.

데이터를 확인하면, 의아한 부분이 생길 수 있습니다. 바로 샘플링된 데이터의 용량 및 개수가 같지 않다는 점 입니다.

반올림을 통해 샘플링 되어야 한다면, 1개~2개만 차이가 있어야 하는데 그렇지 않기 때문입니다.
이러한 데이터 셋을 만들기 위해서는 Random Sampling을 통해야 합니다. Random Sampling을 한다면, 많은 데이터 가공 비용이 들게 됩니다.
비용 효율적인 데이터 가공을 위해 Glue뿐만 아니라, 다른 ETL작업이 가능한 tool에서는 “베르누이 샘플링”을 통해 샘플링을 합니다.

각각의 데이터가 샘플링을 통해 뽑힐 수 있는 확률이 샘플링 비율로 주어지게 됩니다. 이를 통해 Seed를 통해 무작위의 결과를 보장할 수 있으며, 매우 큰 데이터에 대해서도 효율적인 샘플링이 가능하게 됩니다.
Glue Studio에 대해 더 많은 기능이나, 자세히 알고 싶으시면, AWS 문서를 참고하실 수 있습니다.
https://docs.aws.amazon.com/ko_kr/glue/latest/ug/what-is-glue-studio.html
결론
Glue Studio는 Spark 코드의 이해 없이, 그래프 노드 생성만으로 손쉽게 ETL작업을 할 수 있는 SaaS 서비스 입니다.
Hands On의 내용을 review하자면, Glue Crawler를 통해 데이터를 크롤링할 수 있습니다. 이 때는 원본 데이터 전체를 가져오는 것이 아닌, 데이터의 메타데이터만을 가져올 수 있습니다.
데이터 가공에서는 Glue Crawler를 통해 생성한 메타데이터를 가진 데이터 카탈로그를 통해 가공을 할 수 있었지만, 파일 형태로 나타낸 결과들을 통해 눈으로 Hands On의 진행을 확인할 수 있도록 하였습니다.
실무에서는 최후의 최후까지 원본 데이터의 이동을 안하는 Lazy Evaluation의 개념을 적용하여, S3같은 데이터 스토어에 저장하는 것이 아닌, 데이터 카탈로그 형태로 가지고 있어 최종 결과물만 생성하도록 하는 것이 Best Practice이며, 비용효율적일 것 입니다.
다음 Hands On에서는 S3가 아닌, RDS에서 데이터를 가져와 Athena를 통해 쿼리할 수 있는 환경 생성을 준비해보도록 하겠습니다.
이상으로 Hands On을 마치겠습니다.
문의 사항이 있으시면, NDS Sales팀으로 연락 주시길 바랍니다.
cloud.sales@nongshim.co.kr
SA 황성현