
들어가며
Databricks Data + AI Summit 2026에서 인상 깊었던 세션 중 하나는 딜로이트가 발표한 Future-proofing Finance: modernizing banking data (금융 조직이 AI를 실제 업무에 적용하기 위해 어떤 데이터 기반을 준비해야 하는가) 였습니다. 많은 기업이 AI 도입을 검토하고 있지만, 실제 현업 업무에 AI를 적용하려면 단순히 모델을 도입하는 것만으로는 충분하지 않습니다.
특히 금융 영역에서는 데이터의 정확성, 감사 가능성, 업무 맥락, 거버넌스가 매우 중요합니다. AI가 재무 데이터를 분석하거나 의사결정을 지원하려면, 데이터가 신뢰할 수 있어야 하고, 결과가 검증 가능해야 하며, 비즈니스 용어와 프로세스를 일관되게 이해할 수 있어야 합니다.
이번 세션에서는 금융 조직이 AI 도입을 위해 준비해야 할 핵심 전환 방향을 Trust, Validity, Context 세 가지 키워드로 설명했습니다.
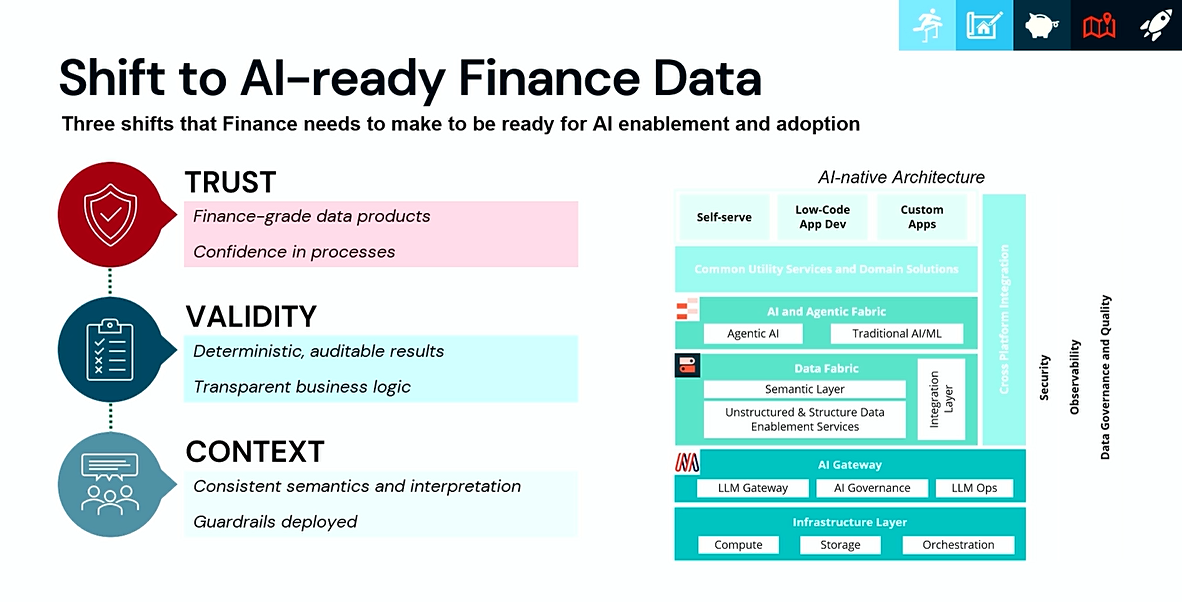
1. AI-ready Finance Data를 위한 세 가지 포인트
첫 번째는 Trust입니다. 금융 데이터는 단순히 수집되어 있는 것만으로는 충분하지 않습니다. 실제 업무에 활용되기 위해서는 Finance-grade data product로 관리되어야 하며, 데이터 생성과 처리 과정에 대한 신뢰가 필요합니다. 즉, 현업 사용자가 데이터를 믿고 사용할 수 있어야 AI 기반 분석과 자동화도 가능해집니다.
두 번째는 Validity입니다. 금융 업무에서는 AI가 생성한 결과가 그럴듯해 보이는 것보다, 결과가 결정론적이고 감사 가능해야 합니다. 어떤 데이터와 로직을 기반으로 결과가 나왔는지 설명할 수 있어야 하며, 비즈니스 로직도 투명하게 관리되어야 합니다. 이는 금융권에서 AI를 실험 수준이 아니라 실제 운영 환경에 적용하기 위한 필수 조건입니다.
세 번째는 Context입니다. AI가 금융 업무를 이해하려면 단순히 데이터 값만 보는 것이 아니라, 데이터가 어떤 의미를 갖는지 알아야 합니다. 동일한 지표라도 부서, 상품, 회계 기준, 리스크 정책에 따라 해석이 달라질 수 있습니다. 따라서 일관된 시맨틱과 해석 체계, 그리고 적절한 guardrail이 필요합니다.
결국 AI-ready Finance Data란 단순히 AI가 접근할 수 있는 데이터가 아니라, 신뢰할 수 있고, 검증 가능하며, 업무 맥락을 포함한 데이터라고 볼 수 있습니다.

2. Finance Data Product 구축
세션에서는 Finance Data Product를 구축하기 위한 필요 요건이 소개되었습니다. 핵심은 지속 가능한 데이터 제품을 빠르게 만들되, 그 안에 데이터 거버넌스를 함께 내재화하는 것입니다.
이를 위해 먼저 Finance data product blueprint가 필요합니다. 프로젝트 중심 사고에서 벗어나 비즈니스 제품 중심으로 전환하고, 데이터 도메인과 유스케이스를 매핑하며, 제품 백로그와 목표 아키텍처를 정의해야 합니다.
다음으로 AI-augmented metadata and data quality가 중요합니다. 금융 데이터에서 중요한 데이터 요소를 식별하고 정의하며, 데이터 품질 규칙을 비즈니스 맥락과 거버넌스 기준에 맞게 관리해야 합니다. 또한 Unity Catalog와 같은 거버넌스 체계를 통해 데이터 계보와 금융 프로세스의 맥락을 연결할 수 있습니다.
이 접근은 세션에서 언급된 Governance by Design과도 연결됩니다. 데이터 제품을 만든 뒤 나중에 거버넌스를 붙이는 것이 아니라, 데이터 흐름, 품질 기준, 계보, 통제 요건을 설계 단계부터 함께 반영하는 방식입니다.
마지막으로 Code Assistant를 활용해 기존 레거시 코드와 복잡한 로직을 이해하고, 노트북 구조나 로직 개선을 제안하며, 오류 탐지와 디버깅을 통해 코드 품질을 높일 수 있습니다. 이는 데이터 제품 개발 속도를 높이는 동시에 운영 품질을 개선하는 데 도움이 됩니다.
결국 Finance Data Product는 단순한 데이터셋이 아니라, 데이터 품질, 메타데이터, 비즈니스 맥락, 거버넌스가 결합된 실행 가능한 데이터 자산이라 볼 수 있습니다.

3. AI-enabled Finance Operations: 금융 업무 운영 방식의 변화
AI-ready Finance Data가 준비되면 금융 조직은 AI-enabled Finance Operations로 확장할 수 있습니다. 세션에서는 2026년 AI concierge 서비스를 확장해 금융 조직이 데이터를 활용하는 과정의 마찰을 줄이는 방향을 소개했습니다.
예를 들어 Code Assist를 통해 Lakehouse 데이터 제품 전달을 가속화하고, Lakebase와 Delta Live Tables를 통해 분석 유스케이스와 실시간 운영 유스케이스 간 균형을 맞출 수 있습니다. 또한 Unity Catalog 기반의 Finance Data Product를 디지털 스토어 형태로 제공하면, 현업 사용자는 필요한 데이터를 더 쉽게 찾고 활용할 수 있습니다.
여기에 Genie를 활용하면 빠른 데이터 탐색과 셀프서비스 분석이 가능해집니다. 금융 사용자는 복잡한 SQL이나 분석 도구를 직접 다루지 않더라도, 자연어 기반으로 데이터를 탐색하고 인사이트를 얻을 수 있습니다.
더 나아가 Agent Bricks를 활용하면 금융 워크플로우 자체를 고도화할 수 있습니다. 데이터 제품 전달과 유지보수 과정을 Agentic 방식으로 자동화하면, 데이터 관리 조직은 반복적인 운영 업무를 줄이고 더 높은 가치의 데이터 제공에 집중할 수 있습니다.
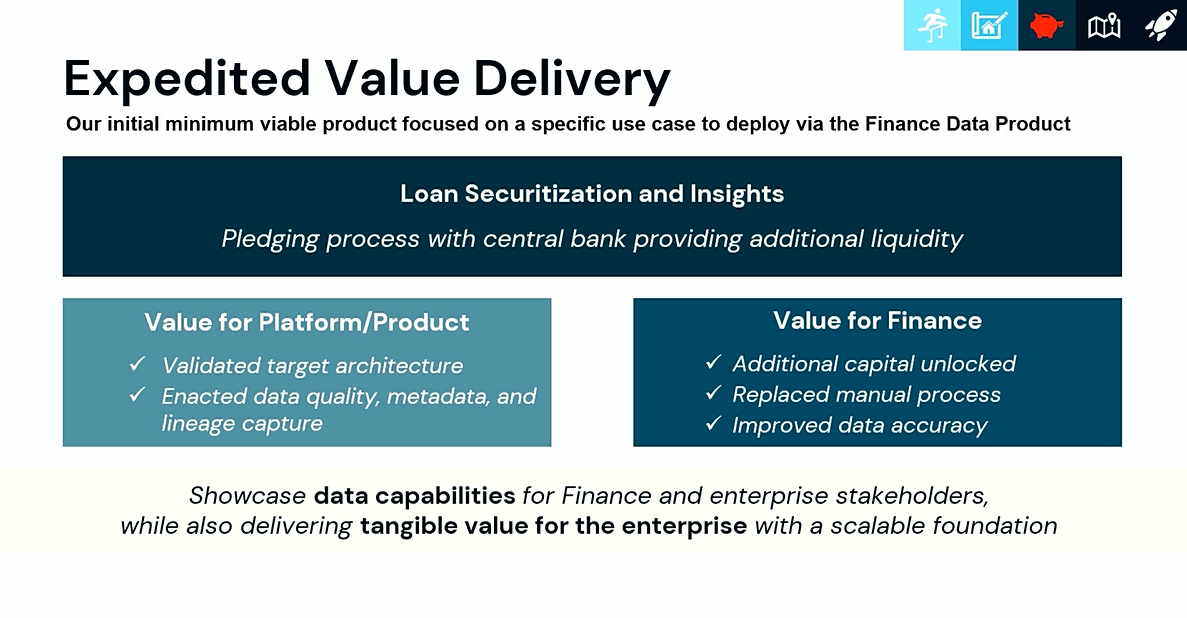
4. 빠른 검증: Loan Securitization 사례
마지막 장표에서는 Finance Data Product를 활용한 초기 MVP(minimum viable product) 사례로 Loan Securitization and Insights가 소개되었습니다. 이는 중앙은행이 추가 유동성을 제공하는 담보 프로세스를 대상으로, Finance Data Product를 통해 빠르게 가치를 검증한 사례입니다.
플랫폼과 제품 관점에서는 목표 아키텍처를 검증하고, 데이터 품질, 메타데이터, 운영관리 작업을 강화하여, 고객의 업무 관점에서는 추가 자본을 확보하고, 수작업 프로세스를 대체하며, 데이터 정확도를 개선하는 성과를 만들었다고 발표하였습니다.
이 사례가 중요한 이유는 AI-ready Finance Data 전략이 단순한 플랫폼 구축 논의에 머무르지 않는다는 점입니다. 실제 금융 사례를 대상으로 MVP를 만들고, 이를 통해 데이터 역량과 비즈니스 가치를 동시에 검증하여 직접적 프로젝트로 만들어낸 사례로 볼 수 있습니다.
마치며
금융 산업에서 AI 도입의 핵심은 모델 자체보다 데이터 준비도에 있습니다. 아무리 뛰어난 AI 모델을 사용하더라도, 데이터가 신뢰할 수 없거나 업무 맥락이 부족하다면 실제 운영 환경에서 활용되기 어렵습니다.
이번 세션은 금융 조직이 AI를 도입하기 위해 어떤 데이터 기반을 준비해야 하는지 명확하게 보여주었습니다. Trust, Validity, Context를 갖춘 Finance Data Product를 만들고, 이를 기반으로 AI-enabled Finance Operations로 확장하는 것이 핵심입니다.
앞으로 금융 조직의 데이터 플랫폼은 단순 분석 환경을 넘어, AI가 업무를 이해하고 안전하게 실행할 수 있도록 돕는 운영 기반으로 발전할 것입니다. AI-ready Finance Data는 그 출발점이라고 볼 수 있습니다.
Presales 장채훈
![Read more about the article [Databricks Data + AI Summit 2026] Oracle에서 Databricks Lakehouse로의 마이그레이션 전략](https://tech.cloud.nongshim.co.kr/wp-content/uploads/2606_databricks.png)
![Read more about the article [Databricks Data + AI Summit 2026] 키노트로 본 Agentic Data 시대의 시작](https://tech.cloud.nongshim.co.kr/wp-content/uploads/IMG_0283-scaled.jpg)