Databricks가 그리는 Agentic Analytics의 미래
GenAI Ontology부터 Lakehouse RT까지, Agentic AI 시대를 위한 새로운 데이터 플랫폼 전략
Databricks Summit 2026에서는 AI와 데이터 플랫폼의 미래를 보여주는 다양한 발표가 이어졌습니다.
그중에서도 개인적으로 가장 인상 깊었던 세션 중 하나는 “Agentic Analytics on Databricks Lakehouse” 세션이었습니다.
최근 AI 업계의 가장 큰 화두는 단연 Agentic AI입니다.
생성형 AI가 등장한 초기에는 문서 요약이나 질의응답 중심의 활용이 주를 이루었습니다. 하지만 이제 AI는 단순히 답변을 생성하는 수준을 넘어 실제 업무를 수행하는 방향으로 발전하고 있습니다.
사용자의 질문을 이해하고, 필요한 데이터를 찾고, 여러 시스템과 연결하여 정보를 수집하고, 분석을 수행한 뒤, 최종 보고서까지 생성하는 것.
이제 이러한 과정 전체를 Agent가 수행하는 시대가 열리고 있습니다.
Databricks는 이번 세션에서 이러한 변화가 데이터 플랫폼에 어떤 영향을 미칠 것인지, 그리고 Agentic AI 시대에 데이터 플랫폼은 어떤 역할을 수행해야 하는지를 매우 흥미로운 관점에서 설명했습니다.
Agentic AI 시대, 데이터 팀이 직면한 새로운 현실
세션에서는 “Jess”라는 가상의 인물을 통해 이야기를 풀어나갔습니다.
Jess는 글로벌 여행 기업인 Wonder Bricks의 Analytics 책임자입니다.
매일 경영진과 현업 부서로부터 수많은 질문을 받습니다.
- 스위스 시장의 예약 완료율은 어떤가?
- APJ(Asia Pacific Japan) 지역 이탈률은 왜 증가하고 있는가?
- 위험 신호가 있는 주요 호텔은 어디인가?
- 최근 프로모션 성과는 어떻게 변화하고 있는가?
문제는 질문의 수는 계속 늘어나지만 데이터 팀의 규모는 그대로라는 점입니다.
많은 기업들이 비슷한 상황을 경험하고 있을 것입니다.
데이터에 대한 수요는 폭발적으로 증가하지만 데이터 전문가의 수는 제한적입니다.
여기에 생성형 AI와 Agent 기술이 등장하면서 현업 사용자들은 더 많은 정보를 직접 얻고 싶어 합니다.
Databricks는 이러한 상황에서 Agent가 데이터 팀의 생산성을 극적으로 향상시킬 수 있다고 설명했습니다.
하지만 동시에 Agent를 기업 환경에 도입하기 위해서는 몇 가지 중요한 과제를 해결해야 한다고 강조했습니다.
Agentic Analytics의 핵심 과제
Databricks는 Agentic Analytics를 구축할 때 고려해야 할 세 가지 핵심 과제를 제시했습니다.
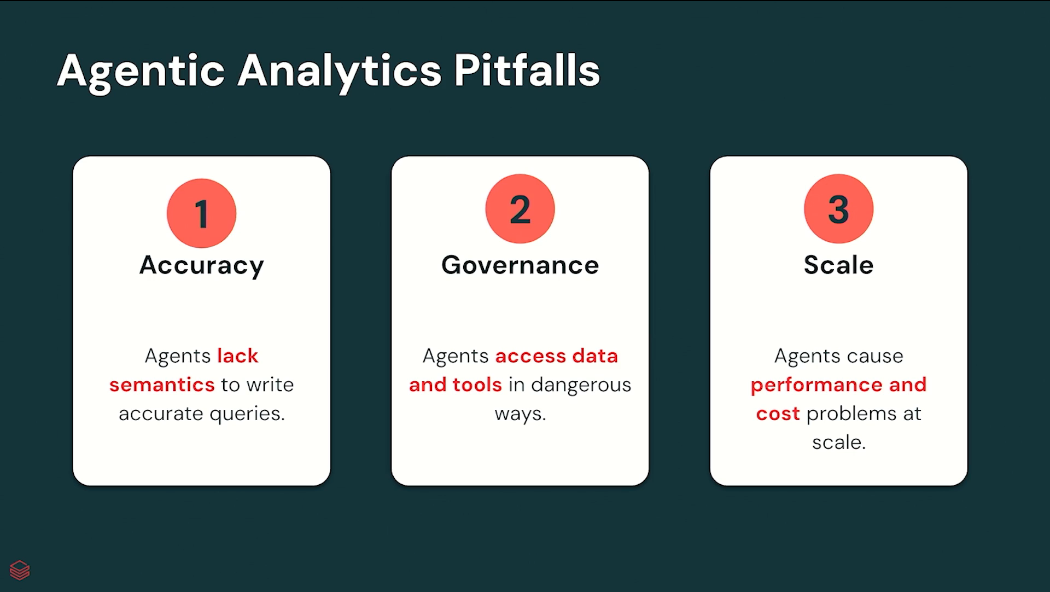
1. 정확성(Accuracy)
Agent는 언어를 이해하지만 기업의 비즈니스 맥락까지 자동으로 이해하지는 못합니다.
예를 들어 다음과 같은 질문을 생각해 보겠습니다.
“위험에 처한 주요 호텔은 어디인가?”
사람은 자연스럽게 이해할 수 있습니다.
하지만 Agent 입장에서는 여러 가지 의문이 생깁니다.
- 주요 호텔이란 무엇인가?
- 예약 기준인가?
- 매출 기준인가?
- 위험이란 무엇을 의미하는가?
- 취소율 증가인가?
- 고객 불만 증가인가?
Agent가 이러한 의미를 이해하지 못하면 잘못된 분석 결과를 생성할 수 있습니다.
2. 거버넌스(Governance)
Agent는 단순한 챗봇이 아닙니다.
데이터베이스에 접근하고,
사내 시스템을 호출하며,
외부 API를 활용하고,
문서를 조회할 수 있습니다.
그만큼 보안과 통제의 중요성이 커집니다.
특히 기업 내부에서는 다양한 조직이 Agent를 개발하게 됩니다.
Databricks는 이를 “Shadow IT” 현상으로 설명했습니다.
데이터 팀만 Agent를 만드는 것이 아니라 마케팅, 영업, 운영 조직도 각자 Agent를 만들게 된다는 것입니다.
결국 기업은 다음과 같은 질문에 답해야 합니다.
- Agent가 어떤 데이터에 접근했는가?
- 어떤 모델이 사용되었는가?
- 어떤 Tool을 호출했는가?
- 누가 해당 Agent를 사용했는가?
3. 확장성(Scale)
Agent 하나를 만드는 것은 어렵지 않습니다.
실제로 많은 조직들이 PoC 단계에서는 성공을 경험합니다.
문제는 그 이후입니다.
1개의 Agent가
10개가 되고
100개가 되고
1,000개가 되면 상황은 완전히 달라집니다.
수많은 Agent가 동시에 SQL을 실행하고 데이터를 조회하기 시작하면 데이터 플랫폼은 새로운 종류의 부하를 감당해야 합니다.
Databricks는 Agentic Analytics가 단순한 AI 문제가 아니라 플랫폼 확장성의 문제이기도 하다고 설명했습니다.
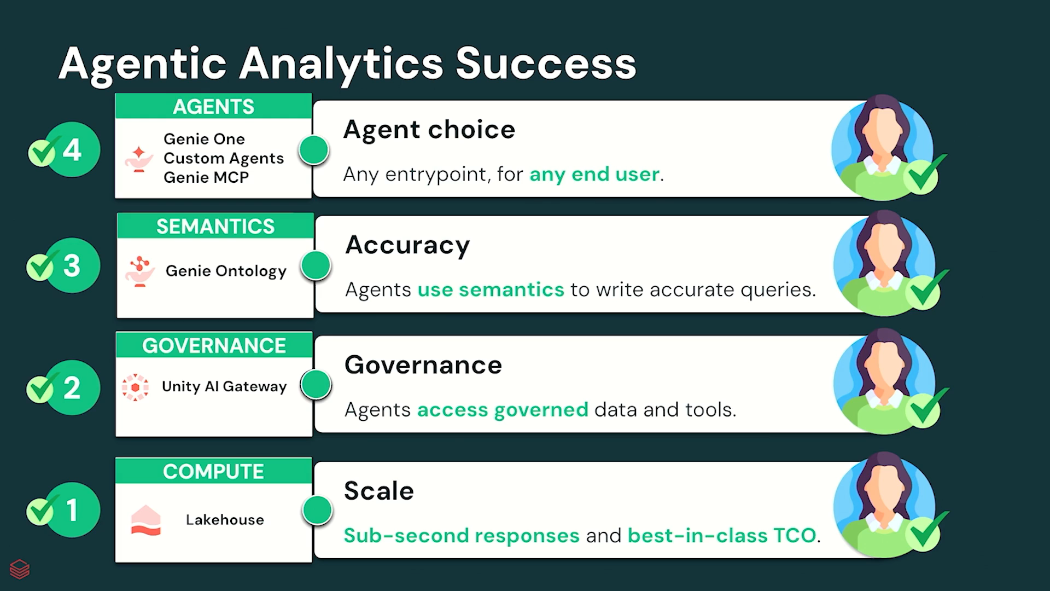
Databricks가 제시한 Agentic Analytics 아키텍처
Databricks는 이러한 문제를 해결하기 위해 4계층 구조의 Agentic Analytics 아키텍처를 제시했습니다.
- Compute
- Governance
- Semantics
- Agent Layer
흥미로운 점은 AI 모델이 중심이 아니라 데이터 플랫폼 자체가 중심이라는 것입니다.
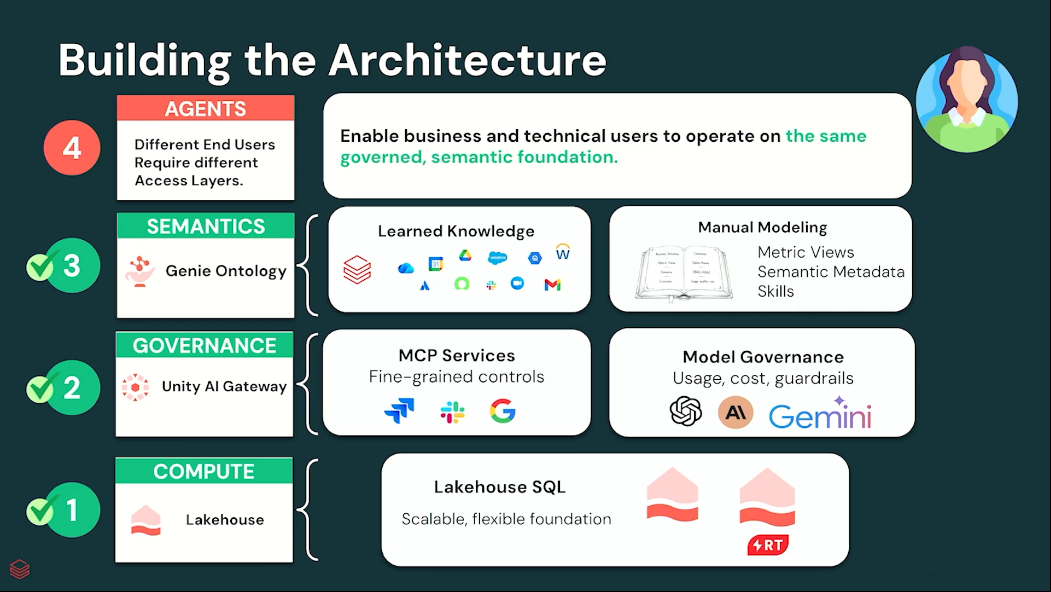
Layer 1. Compute – Lakehouse RT
Agent가 많아질수록 가장 먼저 중요해지는 것은 성능입니다.
Agent는 사용자의 질문에 답하기 위해 끊임없이 데이터를 조회합니다.
Databricks는 이를 위해 새롭게 발표한 Lakehouse RT(Real-Time) 를 소개했습니다.
Lakehouse RT는 Agentic Analytics 환경에 최적화된 초고성능 컴퓨트 엔진입니다.
Databricks가 공개한 벤치마크에 따르면,
10,000개의 대시보드가 동시에 실행되는 환경에서도 약 150ms 수준의 응답 시간을 유지할 수 있다고 설명했습니다.
이는 사실상 수천 개의 Agent가 동시에 데이터 조회를 수행하는 환경을 가정한 수치입니다.
또한 기존 Serverless SQL 역시 지속적으로 성능 개선이 이루어지고 있으며 대규모 테이블 스캔이나 복잡한 분석 워크로드에 최적화되어 있다고 소개했습니다.
Databricks가 강조한 핵심은 다음과 같습니다.
Agent가 늘어날수록 중요한 것은 모델이 아니라 데이터를 얼마나 빠르게 제공할 수 있는가이다.
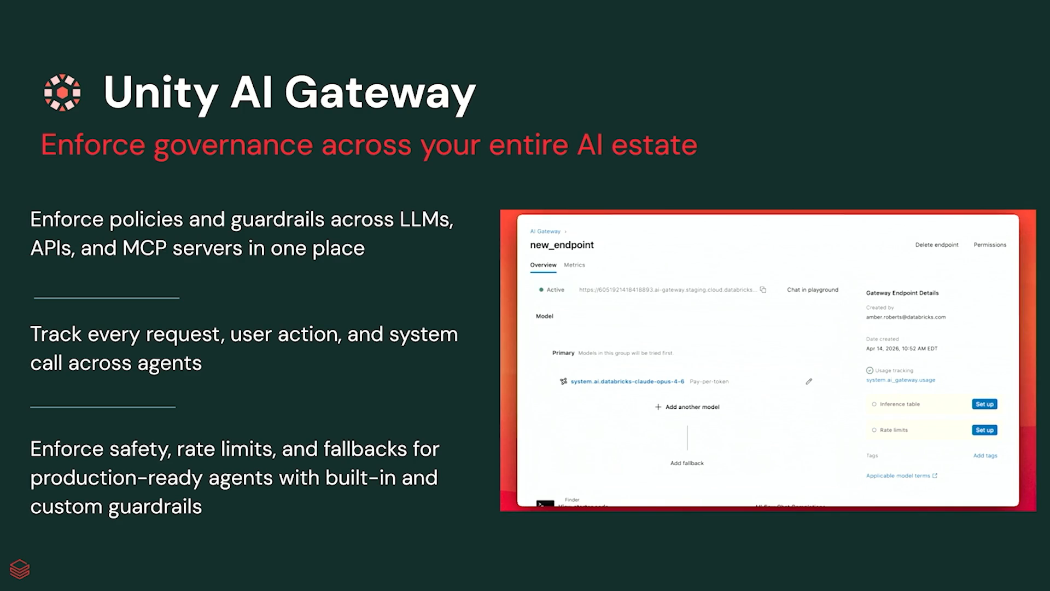
Layer 2. Governance – Unity AI Gateway
두 번째 계층은 거버넌스입니다.
Databricks는 이를 위해 Unity AI Gateway를 제시했습니다.
AI Gateway는 조직 내 모든 AI 요청의 중앙 관문 역할을 수행합니다.
흥미로운 점은 데이터뿐 아니라 모델과 Tool까지 함께 관리한다는 것입니다.
예를 들어 기업이 다음과 같은 환경을 사용한다고 가정해 보겠습니다.
- OpenAI
- Anthropic Claude
- Gemini
- Databricks Hosted Model
- 내부 개발 Agent
AI Gateway는 이러한 모든 모델 호출을 중앙에서 추적할 수 있습니다.
또한 MCP(Model Context Protocol) 기반 Tool 사용 역시 관리할 수 있습니다.
세션에서는 Google Drive MCP 예제가 소개되었습니다.
사용자는 문서를 수정할 권한이 있더라도 Agent에게는 읽기 권한만 부여할 수 있습니다.
즉 사람의 권한과 Agent의 권한을 분리할 수 있는 것입니다.
이러한 정책은 향후 Agent가 실제 업무를 수행하게 될 때 매우 중요한 역할을 하게 될 것으로 보입니다.
Layer 3. Semantics – GenAI Ontology
이번 세션의 핵심이라고 생각되는 부분입니다.
Databricks는 Agentic AI의 가장 어려운 문제가 모델이 아니라 Semantic Layer라고 설명했습니다.
실제로 기업 데이터를 보면 데이터는 존재하지만 의미(Context)는 부족한 경우가 많습니다.
“매출”
이라는 단어 하나만 보더라도 조직마다 정의가 다를 수 있습니다.
영업팀의 매출과 재무팀의 매출은 서로 다른 의미를 가질 수 있습니다.
기존에는 이러한 정보를 다음과 같이 관리했습니다.
- Wiki
- Confluence
- Excel
- PowerPoint
- Markdown 문서
하지만 이러한 방식은 데이터와 의미 체계가 분리되어 있다는 문제가 있습니다.
Databricks는 이를 해결하기 위해 GenAI Ontology 를 발표했습니다.
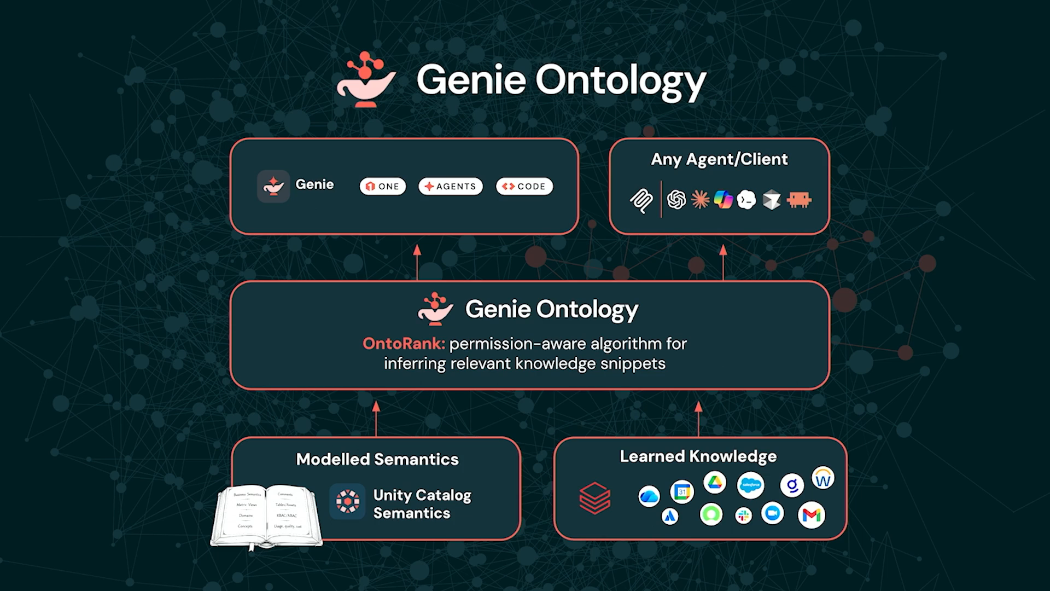
Ontology Snippet
GenAI Ontology는 조직 전체의 의미 체계를 학습하여 Ontology Snippet이라는 형태로 저장합니다.
이 Snippet에는 다음과 같은 정보가 포함됩니다.
- 비즈니스 정의
- 데이터 자산
- 집계 규칙
- 비즈니스 컨텍스트
- 도메인 전문가
- 신뢰도 정보
즉 Agent는 단순히 SQL을 생성하는 것이 아니라 비즈니스 의미를 이해한 후 데이터를 조회하게 됩니다.
OntoRank
또 하나 흥미로운 기능은 OntoRank입니다.
Databricks는 단순히 의미 정보를 저장하는 것에 그치지 않습니다.
어떤 정보가 더 신뢰할 수 있는지까지 판단합니다.
데모에서는 특정 Ontology Snippet 작성자의 전문성과 도메인 경험을 기반으로 신뢰도를 계산하는 모습이 소개되었습니다.
이를 통해 Agent는 상황에 따라 가장 적절한 컨텍스트를 선택할 수 있습니다.
Layer 4. Agent Choice
Databricks는 모든 사용자가 동일한 Agent를 사용할 필요는 없다고 설명했습니다.
사용자의 역할에 따라 적합한 인터페이스가 다르기 때문입니다.
Genie
비즈니스 사용자를 위한 Agent
자연어로 질문하고 답변을 얻을 수 있습니다.
Agent Bricks
개발자와 AI 엔지니어를 위한 Agent 플랫폼
복잡한 멀티 Agent 구성과 Supervisor Agent 구축이 가능합니다.
Genie MCP
Claude, Codex, OpenAI와 같은 외부 Agent에게도 동일한 Semantic Layer를 제공합니다.
결국 Agentic Analytics Success는
“어떤 모델을 사용하느냐”가 아니라
“조직의 데이터, 의미 체계, 거버넌스를 Agent가 얼마나 잘 활용할 수 있느냐”
에 달려 있다고 설명했습니다.
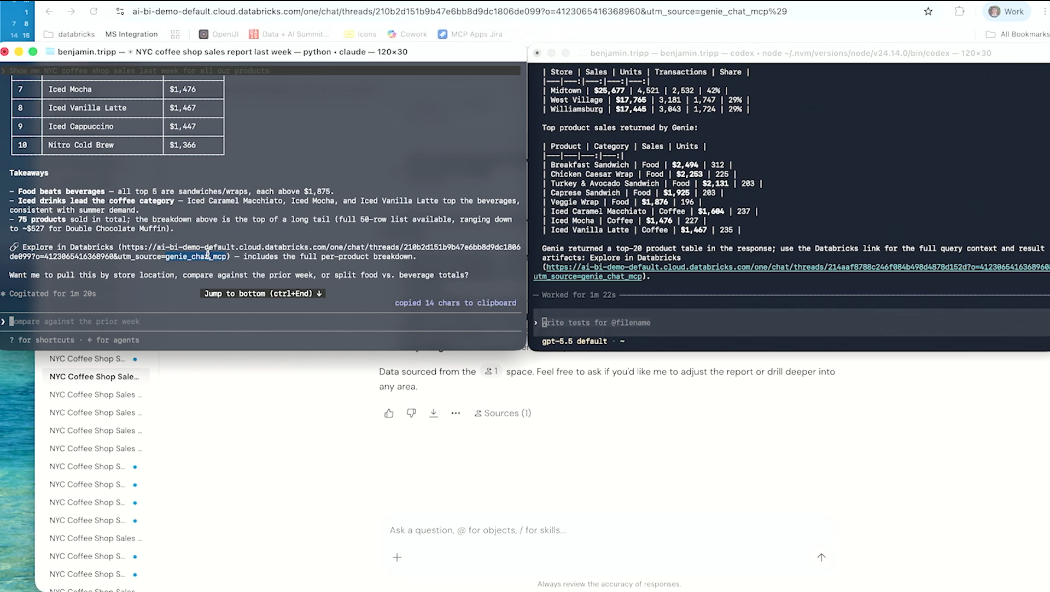
인상적이었던 데모
세션 후반부에는 Claude Code와 Codex를 동시에 실행하는 데모가 진행되었습니다.
흥미로운 점은 서로 다른 Agent임에도 동일한 질문에 대해 동일한 결과를 반환했다는 것입니다.
이유는 간단했습니다.
두 Agent 모두 Genie MCP를 통해 동일한 GenAI Ontology를 참조했기 때문입니다.
즉 Agent는 달라도 의미 체계는 동일한 것입니다.
Databricks는 이를 통해 Single Source of Truth를 구현하고자 합니다.
모든 것은 Trace 된다
또 하나 인상적이었던 기능은 Trace 기능이었습니다.
Databricks는 Agent의 모든 행동을 기록합니다.
- 어떤 Agent가 사용되었는가?
- 어떤 Tool을 호출했는가?
- 어떤 Ontology를 참조했는가?
- 어떤 데이터가 조회되었는가?
- 어떤 추론 과정을 거쳤는가?
이 모든 정보가 중앙에서 추적됩니다.
AI 활용이 증가할수록 Explainability와 Auditability는 필수 요소가 될 것입니다.
Databricks는 이를 플랫폼 수준에서 해결하려는 모습을 보여주었습니다.
마치며
이번 Agentic Analytics 세션은 단순히 새로운 AI 기능을 소개하는 발표가 아니었습니다.
오히려 Agentic AI 시대에 데이터 플랫폼이 어떤 역할을 해야 하는지를 보여주는 청사진에 가까웠습니다.
Databricks는 Agent의 성능 경쟁보다는 Agent가 신뢰할 수 있는 데이터를 활용하도록 만드는 것에 집중하고 있었습니다.
Lakehouse RT를 통한 확장성,
Unity AI Gateway를 통한 거버넌스,
GenAI Ontology를 통한 의미 체계,
그리고 Genie와 Agent Bricks를 통한 다양한 사용자 경험.
이 모든 요소가 결합되어 Databricks가 생각하는 Agentic Analytics 플랫폼이 완성됩니다.
개인적으로는 이번 Summit에서 발표된 수많은 AI 관련 기능 중에서도 GenAI Ontology가 가장 인상 깊었습니다.
AI 모델은 앞으로도 계속 발전할 것입니다.
하지만 기업이 보유한 데이터와 비즈니스 의미 체계는 쉽게 대체할 수 없는 자산입니다.
Databricks는 바로 이 지점에 집중하고 있으며, Agentic AI 시대의 경쟁력은 결국 더 좋은 모델이 아니라 더 정확한 데이터 컨텍스트에서 나온다는 점을 다시 한번 보여준 세션이었습니다.
Reference
https://www.databricks.com/dataaisummit/session/agentic-analytics-databricks-lakehouse
Data Engineer 임신웅
![Read more about the article [Databricks Data + AI Summit 2026] Oracle에서 Databricks Lakehouse로의 마이그레이션 전략](https://tech.cloud.nongshim.co.kr/wp-content/uploads/2606_databricks.png)
![Read more about the article [Databricks Data + AI Summit 2026] 키노트로 본 Agentic Data 시대의 시작](https://tech.cloud.nongshim.co.kr/wp-content/uploads/IMG_0283-scaled.jpg)