데이터베이스를 옮기지 말고 Use Case를 옮겨라
Databricks Summit 2026에서 공개된 Oracle Migration 방법론과 Lakebridge 활용법
Databricks Summit 2026에서는 AI와 Agentic Analytics 관련 발표들이 많은 주목을 받았습니다.
하지만 실제 고객 환경 관점에서 매우 의미 있었던 세션 중 하나는 Oracle 기반 데이터 웨어하우스를 Databricks Lakehouse로 이전하는 방법론을 소개한 세션이었습니다.
이번 세션에서는 수십 년간 운영되어 온 Oracle 데이터 웨어하우스를 어떻게 Databricks로 이전할 수 있는지, 그리고 이를 위해 어떤 전략과 도구를 활용해야 하는지 였습니다.
개인적으로는 단순한 코드 변환이나 데이터 이전이 아니라,
“어떻게 비즈니스 가치를 빠르게 제공하면서 리스크를 최소화할 것인가”
에 초점을 맞춘 점이 인상적이었습니다.
왜 Oracle 마이그레이션은 어려운가?
많은 기업의 Oracle 데이터 웨어하우스는 단순한 데이터베이스가 아닙니다.
20년에서 30년 이상 운영되며 기업의 핵심 업무를 지원해 온 시스템인 경우가 많습니다.
그 안에는 단순히 데이터만 존재하는 것이 아닙니다.
- 수천 개의 테이블과 뷰
- ETL 프로세스
- PL/SQL 패키지
- Stored Procedure
- Materialized View
- Scheduler 작업
- 사용자 정의 데이터 타입(User Defined Type)
- 다양한 BI 리포트
- 수십 년간 축적된 비즈니스 로직
이 모든 요소가 복잡하게 연결되어 있습니다.
Databricks는 세션에서 가장 먼저 다음과 같은 메시지를 강조했습니다.
Oracle 데이터 웨어하우스를 하나의 거대한 시스템으로 바라보지 말고, 비즈니스 Use Case 단위로 분해해야 한다.
첫 번째 Use Case가 프로젝트 성패를 결정한다
첫 번째 Use Case 선정이 매우 중요하다고 설명했습니다.
많은 조직이 가장 크고 복잡한 업무부터 이전하려고 합니다.
하지만 Databricks는 오히려 첫 번째 Use Case는 다음 조건을 만족해야 한다고 설명했습니다.
높은 비즈니스 가치
경영진과 현업이 자주 사용하는 데이터
빠른 구현 가능성
수개월이 아닌 수주 단위 성과
높은 가시성
사용자가 직접 효과를 체감 가능
Databricks의 강점 활용
기존 환경에서 불가능했던 기능 제공
예를 들어,
- Predictive Analytics
- Anomaly Detection
- AI 기반 분석
- 자연어 질의
등이 대표적입니다.
성공적인 마이그레이션의 시작은 Use Case 분석
많은 조직은 마이그레이션을 시작할 때 다음과 같이 접근합니다.
“500TB Oracle 데이터베이스를 Databricks로 옮겨야 한다.”
하지만 Databricks는 전혀 다른 관점을 제시합니다.
실제로 이전해야 하는 것은 데이터베이스 자체가 아니라 데이터베이스 안에서 수행되고 있는 비즈니스 기능입니다.
예를 들어 데이터 웨어하우스 안에는 다음과 같은 다양한 Use Case가 존재합니다.
- 고객 분석
- 매출 분석
- 재고 관리
- 공급망 분석
- 마케팅 캠페인 분석
- 재무 보고
Databricks는 이러한 각각의 Use Case를 독립적인 Migration Unit으로 바라볼 것을 권장했습니다.
Dependency 분석이 중요한 이유
Use Case를 식별한 다음에는 Dependency 분석이 필요합니다.
예를 들어,
고객 데이터 분석
↓
마케팅 성과 분석
↓
경영진 KPI 대시보드
와 같은 구조가 존재할 수 있습니다.
이 경우 고객 데이터 분석이 먼저 이전되어야 이후 단계도 이전할 수 있습니다.
반대로 서로 독립적인 Use Case는 병렬로 이전할 수 있습니다.
Dependency 분석을 통해 다음과 같은 효과를 얻을 수 있습니다.
- Migration 우선순위 결정
- 일정 단축
- 리스크 최소화
- 병렬 수행 가능 영역 식별
Databricks는 이러한 작업이 전체 Migration Strategy의 핵심이라고 설명했습니다.
두 번째 Use Case 정의 후에는 기술 자산 분석이 필요하다
Use Case를 정의했다면 다음 단계는 해당 Use Case에 연결된 기술 자산을 분석하는 것입니다.
Databricks는 이를 Technical Artifact Inventory라고 설명했습니다.
분석 대상은 다음과 같습니다.
Database Artifact
- Table
- View
- Materialized View
- Index
- Sequence
- User Defined Type
ETL Artifact
- PL/SQL Package
- Stored Procedure
- Oracle Scheduler
- Informatica
- DataStage
- ODI
Integration Component
- API
- External Procedure
- Third-party Tool
이러한 분석을 통해 각 Use Case의 복잡도를 평가할 수 있습니다.
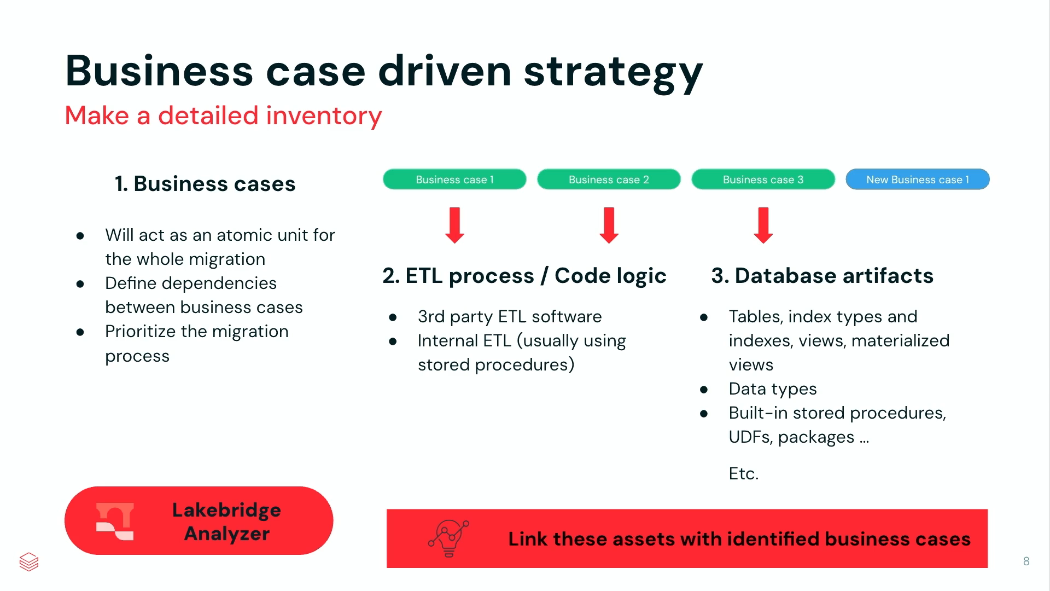
Databricks가 제안한 두 가지 Migration 방법론
Databricks는 크게 두 가지 접근 방식을 제시했습니다.

ETL First
가장 전통적인 Migration 방식입니다.
기존 Oracle 환경의 데이터 흐름을 Databricks에서 그대로 재구성하는 방식입니다.
진행 순서
- 신규 데이터 수집 구축
- 과거 데이터 적재
- ETL 로직 이전
- Data Mart 재구축
- UAT 수행
- Oracle 시스템 제거
장점
- 구조가 명확함
- 리스크 관리가 용이함
- 운영 안정성이 높음
단점
사용자가 성과를 체감하기까지 시간이 오래 걸립니다.
즉, Migration 초기에는 눈에 보이는 변화가 거의 없습니다.
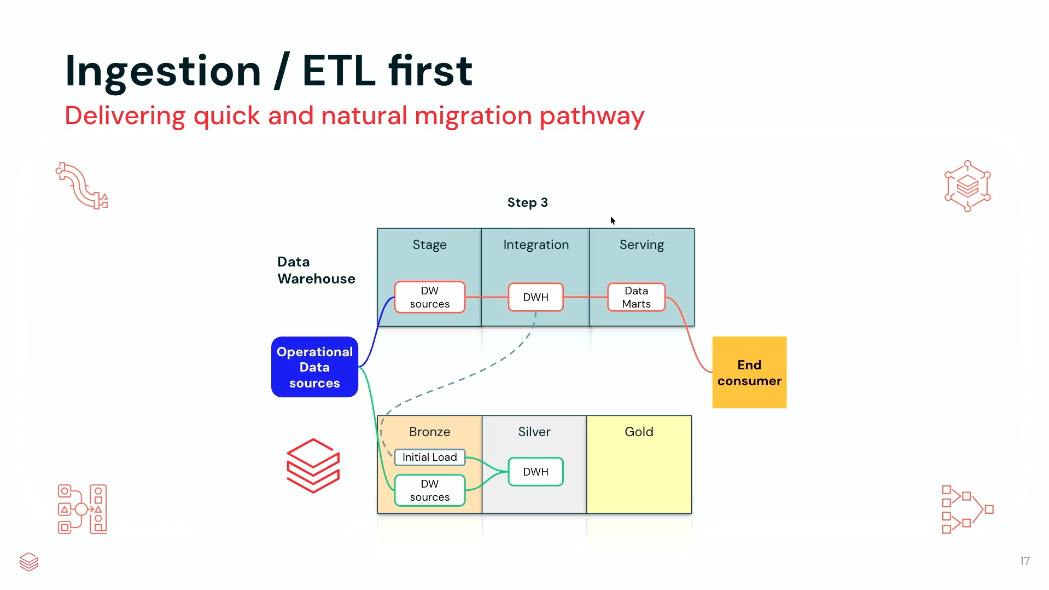
BI First
이번 세션에서 가장 흥미롭게 소개된 방법론입니다.
BI First는 데이터 소비 계층(Serving Layer)부터 이전하는 접근 방식입니다.
진행 순서
- Data Mart를 Databricks로 복제
- BI Tool 연결
- 사용자 활용 시작
- ETL 단계적 이전
- Oracle 제거
장점
사용자가 빠르게 Databricks 환경을 경험할 수 있습니다.
특히 다음과 같은 기능을 조기에 제공할 수 있습니다.
- Databricks SQL
- AI/BI
- Genie
- 자연어 기반 데이터 분석
단점
사용자 입장에서는 Migration이 완료된 것처럼 보일 수 있지만 실제로는 백엔드 ETL이 Oracle에 남아 있을 수 있습니다.
즉, Migration 완료 시점과 사용자 인식 사이에 차이가 발생할 수 있습니다.
Migration 가속화 도구
이번 세션의 후반부에서는 Databricks가 Oracle 데이터 웨어하우스 마이그레이션을 어떻게 가속화할 수 있는지 실제 데모를 통해 소개했습니다.
흥미로웠던 점은 Databricks가 단순히 “코드를 변환해준다”는 수준이 아니라, 마이그레이션 전체 과정을 단계별로 지원하는 도구 체계를 갖추고 있다는 점이었습니다.
발표에서는 다음과 같은 순서로 마이그레이션이 진행되었습니다.
Lakehouse Federation
↓
Lakebridge
↓
GenAI Migration즉, 먼저 기존 Oracle 환경을 Databricks에서 즉시 활용할 수 있도록 연결하고,
그 다음 데이터베이스 객체를 변환하며,
마지막으로 가장 복잡한 ETL 코드까지 자동화하는 흐름입니다.
Step 1. Lakehouse Federation – Oracle을 즉시 Databricks에 연결
가장 먼저 소개된 기능은 Lakehouse Federation입니다.
기존 마이그레이션 프로젝트에서는 데이터를 먼저 복사한 뒤 테스트를 시작하는 경우가 많습니다.
하지만 Federation을 사용하면 Oracle에 저장된 데이터를 Databricks에서 직접 조회할 수 있습니다.
데모에서는 Oracle 데이터베이스와 Databricks를 연결한 후 Foreign Catalog를 생성하는 과정을 보여주었습니다.
연결이 완료되자 Oracle에 존재하던 Schema와 Table이 Databricks Catalog에 그대로 노출되었습니다.
즉, 실제 데이터는 Oracle에 그대로 존재하지만 Databricks 사용자는 마치 Databricks 내부 데이터처럼 조회할 수 있게 되는 것입니다.
이 방식은 특히 BI First 전략에서 매우 유용합니다.
기존 BI 사용자들은 별도의 데이터 이전 작업이 완료되기 전에도 Databricks 환경에서 데이터를 조회하고 분석할 수 있기 때문입니다.
또한 PoC 단계에서도 빠른 검증이 가능합니다.
몇 주 동안 데이터를 복사할 필요 없이 바로 분석 환경을 구성할 수 있기 때문입니다.
Databricks는 이를 통해 마이그레이션 초기 진입 장벽을 크게 낮출 수 있다고 설명했습니다.
Step 2. Lakebridge – Oracle 객체 자동 분석 및 변환
데이터 연결이 완료되면 다음 단계는 데이터베이스 객체 변환입니다.
여기서 사용된 도구가 Lakebridge입니다.
Databricks는 Lakebridge를 단순한 SQL Converter가 아니라 마이그레이션 자동화 플랫폼으로 소개했습니다.
Lakebridge Analyzer
첫 번째 기능은 Analyzer입니다.
Analyzer는 Oracle 환경을 스캔하여 마이그레이션 복잡도를 분석합니다.
예를 들어 다음과 같은 항목들을 자동으로 탐지합니다.
- Table
- View
- Materialized View
- Index
- Sequence
- Stored Procedure
- Package
- User Defined Type
이를 통해 어떤 객체가 쉽게 변환 가능한지,
어떤 객체가 수동 작업이 필요한지,
어떤 부분이 마이그레이션 리스크가 될 수 있는지를 사전에 파악할 수 있습니다.
발표에서는 이를 통해 마이그레이션 일정과 난이도를 보다 정확하게 산정할 수 있다고 설명했습니다.
Lakebridge Converter
복잡도 분석이 끝나면 실제 변환 작업이 진행됩니다.
데모에서는 Oracle DDL 스크립트를 Databricks SQL로 자동 변환하는 과정을 시연했습니다.
예를 들어 Oracle Table DDL은 Databricks Delta Table 형태로 자동 변환되었습니다.
데이터 타입도 자동으로 매핑되었습니다.
CREATE TABLE CUSTOMER ...↓
CREATE TABLE CUSTOMER
USING DELTA
...다만 모든 객체가 100% 자동 변환되는 것은 아니었습니다.
데모에서는 Oracle Sequence가 대표적인 예시로 소개되었습니다.
Oracle에서는 Sequence 객체를 많이 사용하지만 Databricks는 동일한 객체를 제공하지 않습니다.
따라서 Lakebridge는 변환 결과를 생성하면서도
“이 부분은 수동 검토가 필요하다”
라는 정보를 함께 제공합니다.
즉 Lakebridge의 목적은 단순히 코드를 생성하는 것이 아니라 마이그레이션 작업자가 검토해야 할 부분까지 알려주는 것입니다.
Step 3. GenAI Migration – PL/SQL까지 자동 변환
마이그레이션에서 가장 어려운 영역은 ETL 로직입니다.
대부분의 Oracle 환경에서는 수십 년 동안 개발된 PL/SQL Package와 Stored Procedure가 존재합니다.
실제로 많은 프로젝트에서 데이터 이전보다 코드 이전이 훨씬 많은 시간을 차지합니다.
Databricks는 이를 해결하기 위해 새로운 GenAI 기반 Migration 기능을 공개했습니다.
PL/SQL Package 분석
데모에서는 Oracle Package 하나를 선택하여 변환을 수행했습니다.
해당 Package에는 다음과 같은 Oracle 고유 기능들이 포함되어 있었습니다.
- Merge Statement
- Recursive CTE
- CONNECT BY
- Sequence 호출
- Row Count 함수
Databricks는 Migration Project 기능을 통해 해당 코드를 분석하고 자동으로 Databricks SQL Stored Procedure 형태로 변환했습니다.
단순 번역이 아닌 변환 지원
흥미로웠던 점은 단순히 SQL 문법을 치환하는 수준이 아니었다는 것입니다.
변환 과정에서 GenAI는 다음과 같은 작업을 수행했습니다.
- Oracle 문법 분석
- Databricks 호환 코드 생성
- 변환 불가능한 부분 식별
- 수동 수정 필요 영역 표시
- 변환 설명 주석 추가
예를 들어 Oracle Row Count 함수처럼 Databricks에 존재하지 않는 기능은 자동으로 검출되었으며,
Sequence 의존성 역시 별도 검토 항목으로 표시되었습니다.
즉 개발자는 처음부터 모든 코드를 분석하는 대신,
실제로 수정이 필요한 부분에만 집중할 수 있게 됩니다.
데모가 보여준 핵심 메시지
이번 데모의 핵심은 단순히 “AI가 코드를 변환한다”가 아니었습니다.
오히려 Databricks는 마이그레이션 전체 과정을 다음과 같이 체계화하려는 모습을 보여주었습니다.
1단계 – Federation
기존 Oracle 데이터를 즉시 활용
2단계 – Lakebridge
객체 분석 및 SQL 자동 변환
3단계 – GenAI Migration
PL/SQL 및 ETL 로직 자동 변환
결국 Databricks가 보여준 방향은 Oracle 마이그레이션을 대규모 일회성 프로젝트가 아닌, 반복 가능하고 자동화된 프로세스로 전환하는 것이었습니다.
특히 수십 년간 운영된 데이터 웨어하우스를 대상으로 할 때 이러한 자동화 도구들은 단순한 생산성 향상을 넘어 마이그레이션 성공 가능성 자체를 높이는 중요한 요소가 될 것으로 보였습니다.
Oracle 기능은 Databricks에서 어떻게 대체될까?
세션 마지막에는 Oracle 기능과 Databricks 기능의 매핑도 소개되었습니다.
물론 구현 방식은 다르지만 대부분의 핵심 기능은 Databricks에서도 구현 가능합니다.

마치며
이번 세션은 단순한 Oracle Migration 기술 소개 세션이 아니었습니다.
오히려 대규모 엔터프라이즈 환경에서 데이터 플랫폼 현대화를 어떻게 접근해야 하는지를 설명하는 전략 세션에 가까웠습니다.
Databricks가 전달한 메시지는 명확했습니다.
성공적인 마이그레이션은 데이터베이스를 옮기는 프로젝트가 아니라 비즈니스 Use Case를 이전하는 프로젝트다.
그리고 이를 위해서는
- Use Case 중심 접근
- Dependency 분석
- Technical Artifact 분석
- 단계적 Migration Strategy
- Lakebridge 기반 자동화
가 필수적입니다.
특히 이번 Summit에서 공개된 Lakebridge와 GenAI 기반 코드 변환 기능은 Oracle뿐 아니라 Teradata, Netezza 등 다양한 레거시 데이터 웨어하우스 현대화 프로젝트에도 큰 영향을 미칠 것으로 보입니다.
결국 성공적인 마이그레이션의 핵심은 데이터베이스를 얼마나 빨리 옮기느냐가 아니라, 비즈니스 가치를 얼마나 빠르게 제공할 수 있느냐에 있습니다.
데이터베이스를 옮기지 말고 Use Case를 옮겨라.
이번 세션은 Databricks가 생각하는 현대적인 데이터 웨어하우스 마이그레이션 전략을 가장 잘 보여준 사례 중 하나였습니다.
Reference
https://www.databricks.com/dataaisummit/session/migrating-oracle-databricks-lakehouse
Data Engineer 임신웅
![Read more about the article [Databricks Data + AI Summit 2026] 키노트로 본 Agentic Data 시대의 시작](https://tech.cloud.nongshim.co.kr/wp-content/uploads/IMG_0283-scaled.jpg)
![Read more about the article [Databricks Data + AI Summit 2026] AI-ready Finance Data로 전환하기 위한 데이터 플랫폼 전략](https://tech.cloud.nongshim.co.kr/wp-content/uploads/2606_databricks.png)