안녕하세요! 이번 AWS Summit Seoul 2026 에서 가장 뜨거운 관심을 받았던 데이터 및 AI 세션 중 하나를 정리해 보려고 합니다.
바로 “나야, 차세대 OpenSearch: 에이전틱 AI를 곁들인” 세션인데요. 과거의 단순 단어 매칭에서 시작된 검색 기술이 어떻게 AI 에이전트가 스스로 추론하고 다단계로 검색을 수행하는 ‘에이전틱 검색(Agentic Search)’까지 진화했는지, 생생한 발표 내용을 바탕으로 핵심 기술 혁신들을 표와 함께 자세히 알아보겠습니다.
📌 1. 검색 기술의 패러다임 변화
검색 기술은 시대의 흐름과 AI의 발전에 따라 끊임없이 진화해 왔습니다. 발표에서는 이를 총 4단계(어휘 → 의미 → 하이브리드 → 에이전틱)로 나누어 설명했습니다.
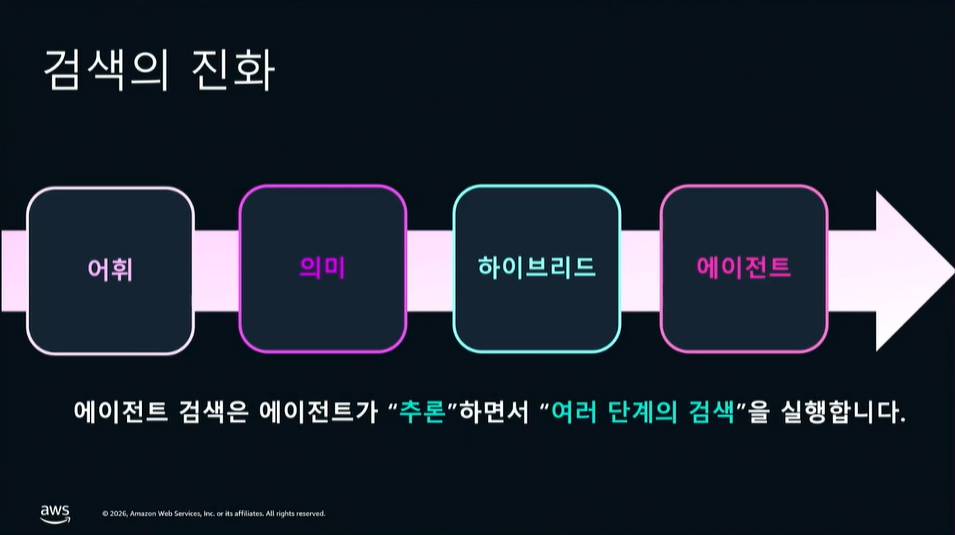
[표 1] 검색 엔진 트렌드의 진화 과정
| 구분 | 어휘 검색 (Lexical Search) | 의미 검색 (Semantic Search) | 하이브리드 검색 (Hybrid Search) | 에이전틱 검색 (Agentic Search) |
|---|---|---|---|---|
| 검색 방식 | 키워드 일치 기반 | 의미 유사도 기반 | 키워드 + 의미 검색 결합 | AI 에이전트가 목적에 따라 검색 수행 |
| 주요 기술 | BM25, TF-IDF | 임베딩(Vector), KNN | BM25 + Vector Search + Reranking | LLM, RAG, Tool Calling |
| 데이터 표현 | 텍스트 | 벡터 임베딩 | 텍스트 + 벡터 | 텍스트 + 벡터 + 외부 시스템 |
| 검색 정확도 | 키워드 의존적 | 문맥 이해 가능 | 정확도 및 재현율 향상 | 상황 및 목적에 따른 추론 가능 |
| 장점 | 빠르고 단순함 | 자연어 질의 지원 | 정확성과 유연성 확보 | 복합적인 문제 해결 가능 |
| 단점 | 동의어·문맥 이해 부족 | 정확한 키워드 매칭 약함 | 구현 복잡성 증가 | 높은 비용 및 복잡성 |
| 대표 활용 사례 | 웹 검색, 로그 검색 | 챗봇, 문서 검색 | 기업 검색, RAG 시스템 | AI 비서, 멀티 에이전트 시스템 |
| OpenSearch 기술 | BM25 | Vector Search | Hybrid Search | Agentic AI + OpenSearch |
🛠️ 2. 운영 간소화와 비용 최적화를 위한 핵심 신기능
대규모 클러스터를 운영하다 보면 성능 병목을 잡기 어렵고, 원본 데이터를 다 저장하느라 스토리지 비용이 치솟기 마련입니다.
Amazon OpenSearch Service는 차세대 버전(3.5 등)에서 이를 자동화와 아키텍처 혁신으로 해결했습니다.

- 🔍 클러스터 인사이트 (Cluster Insights): 어떤 쿼리가 느린지, 어떤 샤드에 부하가 몰리는지 일일이 모니터링할 필요가 없어집니다. 통합 대시보드에서 노드별 성능, 샤드 분포, 쿼리 패턴까지 자동으로 한 페이지에 시각화하여 병목 지점을 빠르게 파악하도록 돕습니다.
- 💾 파생 소스 (Derived Source): 기존 오픈서치는 클러스터 운영을 위해 원본 JSON 문서를 소스 필드에 그대로 중복 저장했습니다. 이 저장을 건너뛰고, 필요할 때 인덱싱된 필드에서 동적으로 원본을 재구성하는 기술입니다.
- 클러스터 스토리지: 최대 40% 절감
- 인덱싱 및 머지 속도: 약 20% 향상
💾 3. 1조 개 벡터 시대를 지탱하는 계층형 스토리지
AI 검색의 근간이 되는 밀집 벡터(Dense Vector) 검색 엔진은 수천만 규모에서 시작해 현재 1조 개(1 Trillion) 이상의 벡터를 지원하는 수준으로 성장했습니다. 문제는 이 막대한 양을 전부 메모리에 올리면 비용이 파산 수준으로 뛴다는 점입니다. 오픈서치는 이를 계층형 스토리지 옵션으로 현실화했습니다.

📊 [표 2] 오픈서치 벡터 스토리지 계층 구조 비교
| 스토리지 계층 Option | 데이터 저장 및 동작 방식 | 비용 측면 | 성능/지연 시간 |
| Exact KNN | 모든 벡터를 하나하나 1:1로 비교 분석 | 연산 비용 가장 높음 | 가장 정확하지만 리소스 소모 큼 |
| 인메모리 (In-Memory) | 근사 검색(ANN) 알고리즘으로 계층적 그래프를 메모리에 빌드 | Exact KNN 대비 저렴 | 초고속 검색 및 높은 성능 제공 |
| 디스크 모드 (Disk Mode) | **양자화(압축)**된 벡터만 메모리에 올리고, 원본 고정밀도 벡터는 디스크에 보관 | 메모리 비용 대폭 절감 (4배~최대 32배 축소) | 메모리에서 후보군 선별 후 디스크 원본으로 재순위화하여 정확도 확보 (약간의 지연 추가) |
| S3 벡터 스토리지 | 벡터 데이터를 Amazon S3에 저렴하게 저장하고 필요시 OpenSearch Serverless로 가져옴 | 가장 저렴한 경제성 | 대규모 장기 보관에 유리, 고성능 저지연 검색 결합 |
⚡ NVIDIA 협업: GPU 인덱스 가속화 (cuVS)
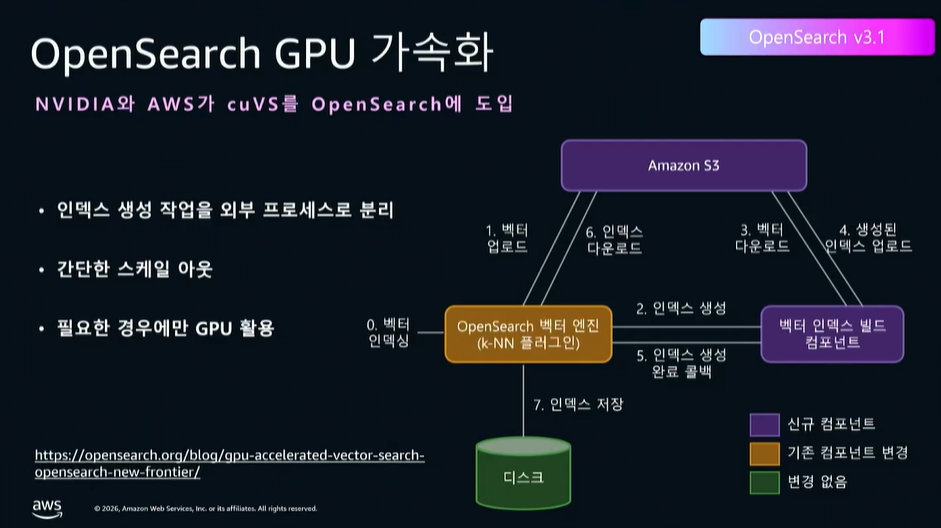
벡터 규모가 커질 때 발생하는 인덱스 생성 속도 문제를 해결하기 위해, 오픈서치에 cuVS(코다 벡터 서치 라이브러리)가 도입되었습니다. 인덱스 생성 작업을 GPU 인스턴스로 오프로드하여 처리하고, 완료되면 GPU를 반환하는 서버리스 GPU 방식을 지원합니다.
- 인덱스 빌드 속도: 벤치마크 기준 최대 10배 향상 (10억 규모 벡터 인덱스를 1시간 이내 구축 가능)
- 빌드 비용: 기존 대비 4분의 1 수준으로 절감
🤖 4. 에이전틱 검색(Agentic Search)의 핵심 메커니즘과 RAG의 한계 극복
지난 수년간 기업들은 단일 쿼리 중심의 정적인 RAG(검색 증강 생성) 패턴을 많이 사용해 왔습니다. 하지만 RAG는 추론이 불가능하고, 복잡한 멀티턴 대화나 반복적인 루프가 필요한 에이전트 시스템에서는 한계를 보입니다. 오픈서치 서비스 버전 3.3부터 기본 탑재된 에이전틱 검색은 단순 검색을 넘어 ‘추론하면서 찾는’ 패러다임을 제안합니다.
🛠️ 에이전틱 검색을 구성하는 3대 핵심 요소
- 🌐 MCP (Model Context Protocol) 표준 지원
- 에이전트 시스템과 외부 데이터를 연결하는 업계 표준 프로토콜인 MCP 서버와 클라이언트를 오픈서치가 직접 구축했습니다. LangChain, LlamaIndex, CrewAI 같은 주요 AI 프레임워크와 별도 커스텀 개발 없이 바로 연동되어 도구를 활용할 수 있습니다.
- 🧠 내부 에이전틱 메모리 (Agentic Memory)
- 에이전트의 단기/장기 세션 메모리뿐만 아니라 이벤트 히스토리까지 오픈서치 내부에서 바로 저장하고 탐색합니다. 만료된 세션 정보는 자동으로 삭제 처리되어 LLM의 컨텍스트 윈도우(Context Window)를 최적화해 줍니다. 완전한 멀티테넌트 구조 기반의 세밀한 권한 관리도 가능합니다.
- 🤖 클러스터 내 전문화된 로컬 에이전트 제공
- 오픈서치 클러스터 내부 환경 안에서 로컬 에이전트가 직접 동작하기 때문에, 인프라의 보안과 권한 경계를 그대로 상속받아 안전합니다. 로그와 트레이스를 통한 옵저버빌리티도 기본 제공됩니다.
📊 [표 3] 오픈서치에서 제공하는 전문화된 3가지 로컬 에이전트 타입
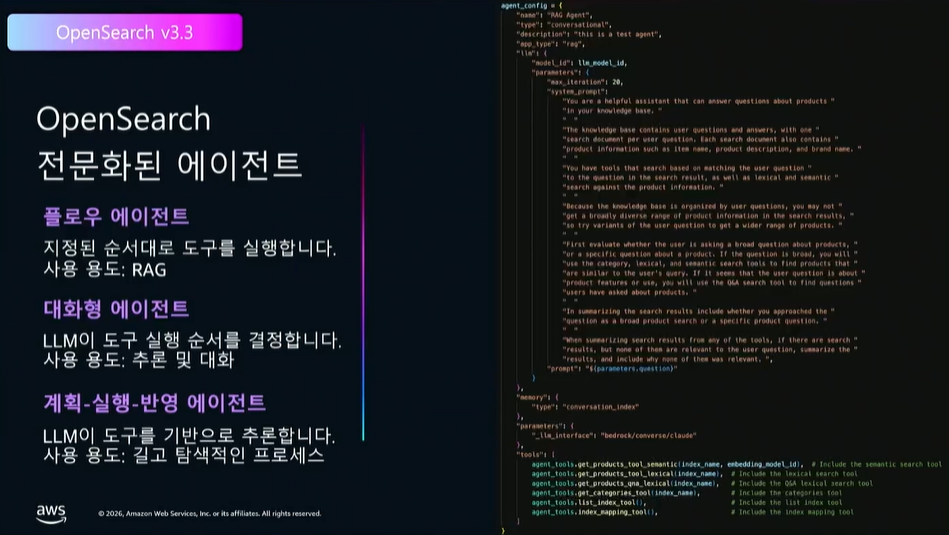
| 에이전트 종류 | 핵심 특징 및 워크로드 | 적합한 유스케이스 |
| 플로우 에이전트 (Flow Agent) | 순차적인 실행 프로세스가 명확히 정의된 구조 | 단일턴(Single-turn) 검색 워크플로우 처리 |
| 대화형 에이전트 (Conversational Agent) | 멀티턴 대화에 최적화, LLM이 어떤 툴을 쓸지 스스로 추론 | 문맥 유지가 필요한 챗봇, 동적 도구 결합 쿼리 |
| 계획 실행 반영 에이전트 (Plan-Execute-Reflect Agent) | 여러 리소스를 넘나들며 탐색적으로 최선의 답을 도출 | 심층 조사 및 분석이 필요한 디렉터 기반 딥 리서치(Deep Research) 작업 |
💡 5. 포스팅을 마치며
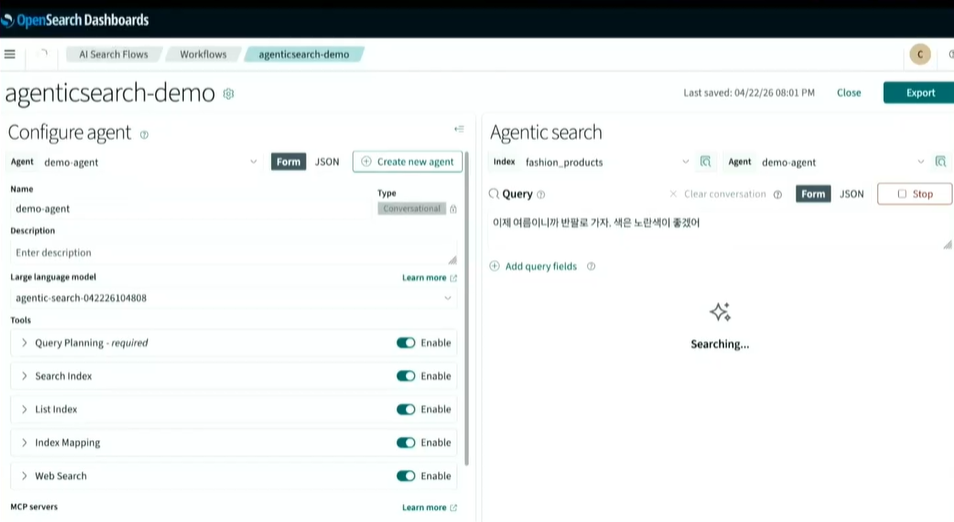
데모 세션에서는 실제 의류 상품 인덱스를 기반으로 에이전틱 검색을 테스트하는 흥미로운 과정이 공개되었습니다.
사용자가 *”여름용 노란색 셔츠를 찾아줘”*라고 질의한 뒤, 대화형 메모리를 켠 상태로 *”그것보단 하얀색이 좋겠어”*라고 문맥으로 입력하자, 에이전트가 이전 대화의 ‘여름’, ‘셔츠’ 필터를 그대로 기억한 채 색상 필터만 하얀색으로 변경하여 동적으로 복잡한 통계 DSL 쿼리를 생성하고 결과를 완벽하게 추려내는 모습을 보여주었습니다. 나아가 Amazon Bedrock LLM과 결합하여 복잡한 통계 데이터의 인사이트까지 자연어로 훌륭하게 정리해 냈습니다.
이제 Amazon OpenSearch는 전통적인 의미의 단순 텍스트 검색 데이터베이스가 아닙니다. 1조 개 규모의 거대한 AI 데이터 벡터를 가장 저렴하고 유연하게 핸들링할 수 있는 저장소이자, 생성형 AI 에이전트가 완벽한 보안 경계 안에서 똑똑하게 추론하고 데이터를 탐색할 수 있게 지원하는 ‘에이전틱 AI 시대의 진정한 코어 인프라 엔지니어링 플랫폼’으로 진화했음을 입증했습니다.
NDS는 안전한 AI 도입을 고민하시는 고객사를 위해, 산업별 규제 요건에 딱 맞춘 맞춤형 AI 아키텍처 설계를 적극 지원합니다. 막연하게 느껴지는 차세대 AI 도입, 이제 NDS의 전문적인 파트너십과 함께 확실한 전략으로 구체화해 보시기 바랍니다.
- 관련 문의: NDS Sales팀 (cloud.sales@nongshim.co.kr)
- 참고: AWS Summit Seoul 2026, AWS Session by 김새롬, 이승철
- 작성: SA 이승복